Apache Lucene(全文检索引擎工具包)
v8.8.2 官方版大小:51.4 MB 更新:2021/04/22
类别:编程工具系统:WinXP, Win7, Win8, Win10, WinAll
分类分类
大小:51.4 MB 更新:2021/04/22
类别:编程工具系统:WinXP, Win7, Win8, Win10, WinAll
Apache
Lucene是一款搜索引擎工具,如果你需要构建搜索类型的软件或者是为应用程序附加全文检索功能就可以选择这款工具编辑搜索和索引方案,软件支持文字分析,用于将文本转换为可索引/可搜索的令牌的API和代码,支持解析多种文件,可以支持多种格式的文档包括HTML,XML,PDF,Word
,可以识别句子的开头和结尾以提供更准确的短语和接近度搜索,让用户快速在文本中找到您输入搜索的内容,添加新的模块分析/
opennlp,其中的分析组件可通过调用相应的OpenNLP工具来执行标记化,词性标记,词形化和短语分块,还提供命名实体识别作为Solr更新请求处理器,如果你需要Apache
Lucene就下载吧!
Lucene通过简单的API提供了强大的功能:
1、可扩展的高性能索引
每小时超过150GB的现代硬件
较小的RAM需求-仅1MB的堆
增量索引与批处理索引一样快
索引大小大约为被索引文本的大小的20-30%
2、强大,准确,高效的搜索算法
排名搜索-最好的结果首先返回
许多强大的查询类型:词组查询,通配符查询,邻近查询,范围查询等
现场搜索(例如标题,作者,内容)
按任何字段排序
合并结果的多索引搜索
允许同时更新和搜索
灵活的分面,突出显示,联接和结果分组
快速,高效存储和耐错字的建议者
可插拔排名模型,包括向量空间模型和Okapi BM25
可配置的存储引擎(编解码器)
3、跨平台解决方案
作为Apache许可下的开源软件提供,使您可以在商业程序和开源程序中使用Lucene
100%纯Java
实现在其他编程语言是指数兼容
Apache Lucene™项目开发了开源搜索软件。该项目发布了一个名为Lucene™core的核心搜索库,以及用于Lucene的python绑定PyLucene。
Lucene Core是一个Java库,提供强大的索引和搜索功能,以及拼写检查,命中突出显示和高级分析/令牌化功能。该PyLucene 子项目提供了Python绑定Lucene的核心。
Lucene PMC很高兴宣布Apache Lucene 8.8.2的发布。
Apache Lucene是完全用Java编写的高性能,功能齐全的文本搜索引擎库。它是一项适用于几乎所有需要全文本搜索的应用程序的技术,尤其是跨平台的应用程序。
Lucene 8.8.2发行要点:
LUCENE-9870:修复Circle2D相交线t值(距离)范围夹
LUCENE-9744:在MinimumShouldMatchIntervalsSource $ MinimumMatchesIterator.getSubMatches()中的简并查询上的NPE。
LUCENE-9762:当查询实现TwoPhaseIterator且重复请求得分时,DoubleValuesSource.fromQuery(也由FunctionScoreQuery.boostByQuery使用)可能会引发异常
要使用Lucene,应用程序应:
1、Document通过添加来 创建Field;
2、创建一个,IndexWriter 并使用为其添加文档addDocument();
3、调用QueryParser.parse() 以从字符串构建查询;和
4、创建一个IndexSearcher 并将查询传递给其search() 方法。
一些简单的代码示例如下:
IndexFiles.java为目录中包含的所有文件创建索引。
SearchFiles.java提示查询并搜索索引。
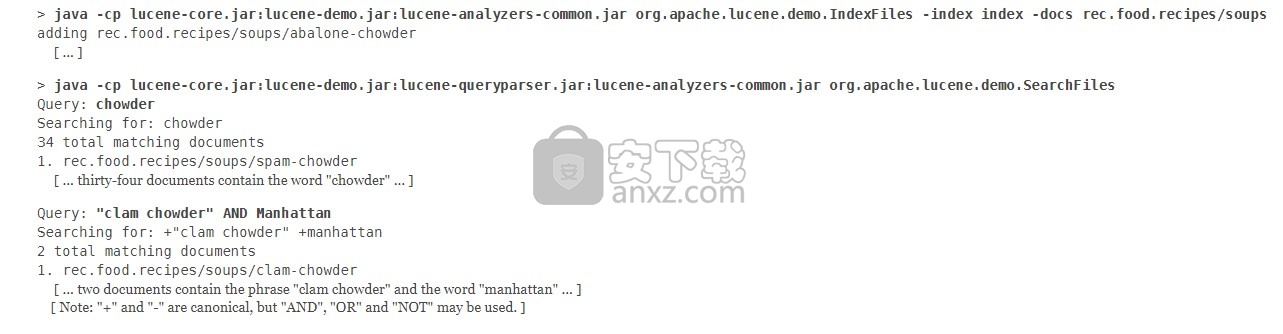
Apache Lucene是高性能,全功能的文本搜索引擎库。 这是一个简单的示例,说明如何使用Lucene进行索引和搜索(使用JUnit来检查结果是否符合我们的预期):
以下内容描述了Lucene评分是如何从基础信息检索模型演变为(有效的)实现的。我们首先简要介绍VSM评分,然后从中衍生出Lucene的概念评分公式,最后从中发展出Lucene的实用评分功能 (后者与Lucene类和方法直接相关)。
Lucene将 信息检索的布尔模型(BM)与信息检索 的 向量空间模型(VSM)结合在一起 -由BM“批准”的文档由VSM评分。
在VSM中,文档和查询表示为多维空间中的加权向量,其中每个不同的索引项是一个维,而权重是 Tf-idf值。
VSM不需要将权重设为Tf-idf值,但是据信Tf-idf值可以产生高质量的搜索结果,因此Lucene使用Tf-idf。 TF和IDF在下面更详细的描述,但现在,完成,我们只能说,对于给定的期限ŧ和文件(或查询)X, TF(T,X)与项目的出现的数量而变化ŧ在X (当一个增加时,另一个增加)和 idf(t)类似地随着包含项t的索引文档的数量的倒数而变化。
VSM得分文档的d查询q是 余弦相似度 的加权矢量查询的V(q)的和V(d) :
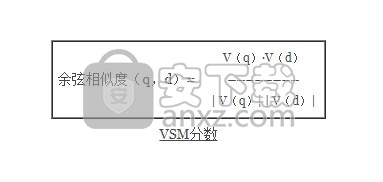
其中V(q) · V(d)是 加权矢量的 点积,| V(q)| 和| V(d)| 是他们的 欧几里得准则。
注意:在将V(q)除以其欧氏范数将其归一化为单位矢量的意义上,上式可以看作是归一化加权矢量的点积 。
Lucene改进了VSM得分,以提高搜索质量和可用性:
众所周知,将V(d)归一化为单位矢量是有问题的,因为它会删除所有文档长度信息。对于某些文档,删除此信息可能是可以的,例如,通过将某个段落复制10次而制成的文档,尤其是在该段落由不同的术语构成的情况下。但是对于不包含重复段落的文档,这可能是错误的。为避免此问题,使用了不同的文档长度归一化因子,该归一化因子归一化为等于或大于单位向量的向量:doc-len-norm(d)。
在建立索引时,用户可以通过分配文档提升来指定某些文档比其他文档更重要。为此,每个文档的分数也要乘以其提升值 doc-boost(d)。
Lucene是基于字段的,因此每个查询词都适用于单个字段,文档长度归一化取决于特定字段的长度,并且除了文档提升外,还有文档字段提升。
可以在索引过程中多次将同一字段添加到文档中,因此该字段的提升是该字段在文档中单独添加(或部分)的提升的乘积。
在搜索时,用户可以指定对每个查询,子查询和每个查询词的提升,因此,将查询词对文档分数的贡献乘以该查询词的提升对query-boost(q)的贡献。
一个文档可以匹配一个多词查询,而不包含该查询的所有词(这对某些查询是正确的)。
在简化了索引中单个字段的假设下,我们得到了Lucene的概念评分公式:
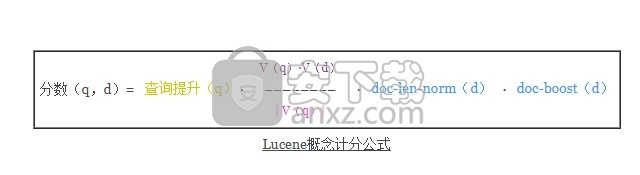
从以下方面来说,概念公式是一种简化:(1)列出了术语和文档,并且(2)提升通常是针对每个查询术语而不是针对每个查询。
现在,我们描述Lucene如何实施此概念评分公式,并从中得出Lucene的实用评分功能。
为了进行有效的分数计算,预先计算并汇总了一些得分成分:
搜索开始时便会知道查询的查询升压(实际上是每个查询词)。
查询欧几里得范数| V(q)| 可以在搜索开始时进行计算,因为它与要打分的文档无关。从搜索优化的角度来看,为什么要费心对查询进行归一化是一个有效的问题,因为所有记分的文档都将被乘以相同的| V(q)|。,因此文档排名(按分数排序)不会受到此规范化的影响。保持此规范化有两个很好的理由:
回想一下, 可以使用 余弦相似度来查找两个文档的相似度。可以使用Lucene例如进行聚类,并使用文档作为查询来计算其与其他文档的相似性。在这种情况下使用是很重要的文件的分数D3 查询D1是媲美得分文档的D3 查询D2。换句话说,两个不同查询的文档分数应该是可比的。还有其他应用程序可能需要这样做。这正是规范化查询向量V(q)所 提供的:两个或多个查询的可比较性(在一定程度上)。
在编制索引时,已知文档长度规范doc-len-norm(d)和文档增强doc-boost(d)。它们是预先计算的,并且它们的乘积在索引norm(d)中保存为单个值。(在以下等式中,norm(t in d)表示norm(field d在doc d中) ,其中field(t)是与项t关联的字段。)
Lucene的实用计分功能是从上面得出的。颜色代码说明了它与概念公式的关系:

1、tf(t in d) 与术语的频率相关,定义为术语t在当前打分的文档d中出现的次数。给定术语出现次数更多的文档获得更高的分数。请注意, tf(t in q)假定为1,因此它不会出现在此等式中。但是,如果查询包含两次相同的项,则将有两个具有相同项的项查询,因此计算仍将是正确的(尽管不是很有效)。tf(t in d) in 的默认计算为ClassicSimilarity:

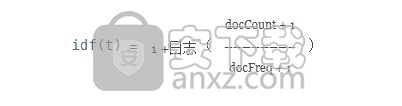
2、idf(t)代表反文档频率。此值与docFreq的倒数 ( t出现在其中的文档数)相关。这意味着较少的术语对总分有较高的贡献。 idf(t)在查询和文档中都显示为t,因此在等式中平方。idf(t) in 的默认计算为ClassicSimilarity:
3、t.getBoost() 是查询文本中指定的查询q中项t的搜索时间提升(请参阅查询语法),或者通过用换行来设置 。请注意,实际上没有直接的API可以在多词查询中访问一个词的增强词,但是多个词在查询中表示为多个 对象,因此可以通过调用sub来访问查询中一个词的词缀。 -query 。 BoostQueryTermQuerygetBoost()
4、norm(t,d)是一个索引时间提升因子,它仅取决于文档中该字段的标记数量,因此较短的字段对得分贡献更大
1、org.apache.lucene:顶级程序包。
2、org.apache.lucene.analysis:文字分析。
3、org.apache.lucene.analysis.standard:快速,通用的基于语法的令牌生成器根据Unicode标准附件#29中的StandardTokenizer 规定,通过Unicode文本分段算法实现分词规则 。
4、org.apache.lucene.analysis.token属性:文本分析的通用属性。
5、org.apache.lucene.codecs:编解码器API:用于自定义索引编码和结构的API。
6、org.apache.lucene.codecs.blocktree:BlockTree术语词典。
7、org.apache.lucene.codecs.compressing:StoredFieldsFormat,它允许对存储的字段进行跨文档和跨字段的压缩。
8、org.apache.lucene.codecs.lucene50:Lucene 5.0索引格式的组件有关索引格式org.apache.lucene.codecs.lucene50的概述,请参见。
9、org.apache.lucene.codecs.lucene60:Lucene 6.0索引格式的组件。
10、org.apache.lucene.codecs.lucene62:Lucene 6.2索引格式的组件有关org.apache.lucene.codecs.lucene70当前索引格式的概述,请参见。
11、org.apache.lucene.codecs.lucene70:Lucene 7.0文件格式。
12、org.apache.lucene.codecs.perfield:可以将每个字段委派为不同格式的帖子格式。
13、org.apache.lucene.document:Document用于索引和搜索的a的逻辑表示。
14、org.apache.lucene.geo:Lucene Core的地理空间实用程序实现
15、org.apache.lucene.index:维护和访问索引的代码。
16、org.apache.lucene.search:代码以搜索索引。
17、org.apache.lucene.search.similarities:该软件包包含可在Lucene中使用的各种排名模型。
18、org.apache.lucene.search.spans:跨度的演算。
19、org.apache.lucene.store:二进制I / O API,用于所有索引数据。
20、org.apache.lucene.util:一些实用程序类。
21、org.apache.lucene.util.automaton:用于正则表达式的有限状态自动机。
22、org.apache.lucene.util.bkd:块KD树,实现在所描述的通用的空间数据结构 本文。
23、org.apache.lucene.util.fst:有限状态传感器
24、org.apache.lucene.util.graph:用于将令牌流作为图形使用的实用程序类。
25、org.apache.lucene.util.mutable:可比对象包装器
26、org.apache.lucene.util.packed:压缩整数数组和流。
Embarcadero RAD Studio(多功能应用程序开发工具) 编程工具177.22 MB12
详情猿编程客户端 编程工具173.32 MB4.16.0
详情猿编程 编程工具173.32 MB4.16.0
详情VSCodium(VScode二进制版本) 编程工具76.23 MBv1.57.1
详情aardio(桌面软件快速开发) 编程工具9.72 MBv35.69.2
详情一鹤快手(AAuto Studio) 编程工具9.72 MBv35.69.2
详情ILSpy(.Net反编译) 编程工具3.97 MBv8.0.0.7339 绿色
详情文本编辑器 Notepad++ 编程工具7.81 MBv8.1.3 官方中文版
详情核桃编程 编程工具272.43 MBv2.1.120.0 官方版
详情delphi2007完整 编程工具1198 MB附安装教程
详情SAPIEN PrimalScript2015 编程工具78.02 MB附带安装教程
详情Alchemy Catalyst可视化汉化工具 编程工具81.00 MBv13.1.240
详情Professional Tag Editor(通用标签编辑器) 编程工具25.6 MBv1.0.6.8
详情Coffeecup HTML Editor(html网页编辑器) 编程工具68.98 MBv15.4 特别版
详情JCreator Pro 编程工具9.65 MBv5.0.1 汉化
详情WebStorm 12中文 编程工具209.88 MB附带安装教程
详情MSWLogo(多功能项目开发与管理工具) 编程工具2.25 MBv6.5 免费版
详情JetBrains datagrip 2018.2.1中文-datagrip 2018.2.1 编程工具160.88 MB附注册码汉化包
详情易安卓5.0 编程工具202 MBv5.0 附破解补丁
详情keil uvision5 编程工具271.63 MB附带安装教程
详情CIMCO Edit V8中文 编程工具248 MB附安装教程
详情IntelliJ IDEA 2020.1(java集成开发环境) 编程工具643.0 MB附安装教程
详情redis desktop manager2020.1中文 编程工具32.52 MB附带安装教程
详情猿编程 编程工具173.32 MB4.16.0
详情信捷PLC编程工具软件 编程工具14.4 MBv3.5.2 官方版
详情源码编辑器 编程工具201.0 MBv3.4.3 官方版
详情Microsoft Visual C++ 编程工具226.00 MBv6.0 SP6 简体中文版
详情s7 200 smart编程软件 编程工具187 MBv2.2 官方中文版
详情TouchWin编辑工具(信捷触摸屏编程软件) 编程工具55.69 MBv2.D2c 官方版
详情易语言5.8完美 编程工具312 MB5.8.1 破解增强版
详情Scraino(少儿编程软件) 编程工具272.93 MBv0.3.0 官方版
详情vs2008中文 编程工具1495 MB附序列号
详情e盾网络验证源码 编程工具25.77 MBV45 官方版
详情codeblocks 编程工具95.21 MBv13.12 中文完整版(带GNW编译器
详情Android Studio(安卓开发环境) 编程工具983.0 MBv3.5.0.21 汉化版(附安装教程)
详情源码编辑器pc版 编程工具201.0 MBv3.4.3 官方版
详情CH341A编程器 编程工具1.06 MB1.30 绿色中文版
详情layuiAdmin pro(layui后台管理模板系统) 编程工具0.57 MBv1.1.0 单页版
详情海龟编辑器 编程工具71.5 MBv0.8.4 中文版
详情Ardublock中文版(Arduino图形化编程软件) 编程工具2.65 MB附带安装教程
详情文本编辑器 Notepad++ 编程工具7.81 MBv8.1.3 官方中文版
详情富途牛牛 编程工具160.59 MBv11.8.9068 官方版
详情微信开发者工具 编程工具129.37 MBv1.05.2105170 官方版
详情UEStudio v18.0.0.18 简体中文绿色 编程工具19.00 MB
详情十六进制编辑器 WinHex 编程工具2.79 MBv20.2 SR-5
详情代码编辑器 Sublime Text 编程工具54.74 MBv4.0.0.4126
详情RJ TextEd(代码编辑器) 编程工具49.46 MBv15.31
详情核桃编程 编程工具272.43 MBv2.1.120.0 官方版
详情影刀 编程工具306.37 MBv4.9.14
详情Kate(高级文本编辑器) 编程工具56.11 MBv21.12.1.1544
详情