
大话数据结构
pdf扫描版大小:37.64 MB 更新:2019/07/29
类别:电子阅读系统:WinXP, Win7, Win8, Win10, WinAll
分类分类
大小:37.64 MB 更新:2019/07/29
类别:电子阅读系统:WinXP, Win7, Win8, Win10, WinAll
大话数据结构pdf扫描版是一款关于计算机的详细资料库程序,在学习计算机知识的过程中,需要设计的知识面特别广,其难度系数就随之而上升,今天小编为大家推荐了该款书籍,可以帮助用户解决在学习过程中遇到的困难,该书籍详细的记录了不同的要点,用户可以通过阅读的方式学习它,该程序支持扫描阅读,这样可以大幅度提高用户的阅读效率以及缩短学习周期;用户如果想深入学习计算机;那么小编强烈的推荐该款程序,可以有效的帮助用户学习;需要的用户赶快下载体验吧
本书以一个计算机教师教学为场景,讲解数据结构和相关算法的知识。通篇以一种趣味方式来叙述,大量引用了各种各样的生活知识来类比,并充分运用图形语言来体现抽象内容,对数据结构所涉及到的一些经典算法做到逐行分析、多算法比较与市场上的同类数据结构图书相比,本书内容趣味易读,算法讲解细致深刻,是一本非常适合自学的读物。
本书主要内容包含:数据结构介绍、算法推导大O阶的方法:顺序结构与链式结构差异、栈与队列的应用:串的朴素模式匹配、KMP模式匹配算法:二叉树前中后序遍历、赫夫曼树及应用;图的深度、广度遍历;最小生成树两种算法、最短路径两种算法:拓扑排序与关键路径算法:折半查找、插值查找、斐波那契查找等静态查找:稠密索引、分块索引、倒排索引等索引技术;二叉排序树、平衡二叉树等动态查找:B树、B+树技术,散列表技术;冒泡、选择、插入等简单排序;希尔、堆、归并、快速等改进排序本书适合学过一门编程语言的各类读者,包括在读的大中专计算机专业学生、想转行做开发的非专业人员、欲考计算机研究生的应届或在职人员,以及工作后需要补学或温习数据结构和算法的程序员等
1.趣味引导
大部分的编程类图书,在内容上基本都是直奔主题。但是尼采曾说过:“人们无法理解他没有经历过的事情。”换句话说,我们只接受过去早已理解的事物相关的信息。这是一种比较学习过程,在这个过程中,大脑寻找每条信息之间的联系。所以教育专家普遍认为,吸引学生的注意力,比较好的办法是用他们比较熟知的知识开始。
因此在本书中,我会用一个故事、一个趣味题目、一部电影的介绍等形式来作为每一章甚至很多小节的开头,选择的内容也多多少少与要讲的主题内容相关。这并不是多余,而是有意为之。事实上,这样的形式在我的前一本书中已经得到了普遍认可。
2.图文并茂
西方有句谚语,“A picture is worth a thousand words.(一图值千言)”。用上千个字描述不明白的东西,很可能一张图就能解释清楚。
我非常认可这个观点,所以本书虽没有达到每一页都有图,但基本做到了绝大部分讲解都有相关图示,关键算法更是通过多图逐步分解剖析。尽管这带来了写作上的难度,但却可以达到较好的效果。毕竟,读者通过本书开始学习数据结构时,要从一无所知或略知一二到完全理解,甚至掌握应用,是需要一个比较艰苦的过程,用大量的图示可以减少这个过程的长度。
3.代码详解
我在写作中尽量摒弃了传统数据结构教材的“重理论思想而轻代码讲解”的作法。在准备数据结构写作时我发现,很多教材对数据结构理论和算法设计思想讲得比较好,可一到实际代码时,有的把代码贴出来加少量注释,有的直接用伪代码形式。这对于上课的学生还好,毕竟有老师在课堂中去详解代码编写原理,可是对于初学数据结构和算法的自学者而言,如果书中不去解释代码某些细节为什么那样编写的原因,甚至代码根本不可能在某个编译器中运行通过,其挫折感是很强烈的。比如即使理解了图结构中的最短路径求解原理,也可能无法写出最短路径的算法。
我把代码在运行过程中变量的变化融入到整个算法设计思想的讲解中,配合相应的示意图,会帮助大家更加容易理解算法的实质。这种讲解模式在本书的第6、7、8、9章的很多复杂算法中有具体体现,越是复杂的代码越是讲解细致。这算是本书的一个特色,希望对读者有帮助。
4.形式新颖
我把本书的内容虚构成了一个老师上课的场景,所有内容都通过这位老师表达出来,书中的文字非常口语化,这样做的目的是为了更加直观地让读者感觉,自己是在学习,是在上课。有人可能会说,现在的课堂大都是让人昏昏欲睡,把读者带入上课场景,不是更加让读者犯困吗?我觉得如果你的学习经历中听过一些优秀老师的课,你就不会下这样的结论。好的老师讲课,是可以做到引人入胜的。
有人可能会问,我为什么不用《大话设计模式》中的对话形式,而采用讲课形式呢?这是对数据结构这门学问的特点考虑的。设计模式主要都是思想体现,通常会仁者见仁、智者见智,用对话展开比较容易;而数据结构中更多的是定义、术语、经典算法等,这些公认的知识,可讨论的地方并不多,更多的是需要把它讲清楚。让两个人在一起讨论某个设计模式的优缺点,会非常合适,而讨论数据结构定义的好坏,就没有太大意义了,不如让一个老师告诉学生数据结构的定义好在哪里更符合实际。因此用传统的讲课形式会好一些。
另外,本书没有习题,有思考的题目也一定会给出某种答案。但本书每个复杂知识点的末尾,都会提供另一本书的进一步阅读建议。这也是基于它是一本自学读物的原则。读者阅读本书可能是任何时间任何地方,如果书中存在没有解答的习题,碰到了困难是没法及时找到老师来帮助的,因此本书尽量避免让读者有这样的困惑存在。如果需要练习的同学,我觉得还是应该考虑再去买本习题集来学习。学习数据结构和算法,做题和上机写代码非常有必要,从这个角度也说明,阅读完本书其实也只是完成入门而已。
本书既然是以老师上课的形式来进行,那就免不了要融入一名教师除了授业解惑以外,还要传达一些个人价值观的体现。书中很多细微处,如对某位科学家的尊敬、对某个算法的推崇、对勤奋励志故事的讲述等都在表达着一个老师向学生传递真、善、美的意愿。我始终认为,读者拿到的虽然只是一本没有表情、不会说话的书,但其实也是在隔空与另一个朋友交流。人与人的交流不可能只是就事论事,一定会有情感的沟通,这种情感如果能产生共鸣、达成互信,就会让事情(比如学习数据结构与算法这件事)本身更容易理解和接受。
本书主要是按照教育部关于计算机专业数据结构课程大纲的要求略微增减来组织内容的。
主要包括:数据结构介绍,算法推导大O阶的方法,线性表结构的介绍,顺序结构与链式结构差异,栈与队列的应用,串的朴素模式匹配、KMP模式匹配算法,树结构的介绍,二叉树前中后序遍历,线索二叉树,赫夫曼树及应用,图结构的介绍,图的深度、广度遍历,最小生成树两种算法,最短路径两种算法,拓扑排序与关键路径算法,查找应用的相关介绍,折半查找、插值查找、斐波那契查找等静态查找,稠密索引、分块索引、倒排索引等索引技术,二叉排序树、平衡二叉树等动态查找,B树、B+树技术,散列表技术,排序应用的相关介绍,冒泡、选择、插入等简单排序,希尔、堆、归并、快速等改进排序,各位排序算法的对比等。

数据结构是计算机软件相关专业的基础课程,几乎可以说,要想从事编程工作,无论你是否是科班出身,都不可以绕过这部分知识。因此,适合阅读本书的读者非常广泛,包括在读的本专科、中专职高技校等计算机专业学生、想转行做开发的非专业人员、欲考计算机研究生的应届或在职人员,以及工作后需要补学或温习数据结构和算法的程序员等各类读者。
本书对读者的技术背影要求比较低,只要是学过一门高级编程语言,例如C、C++、Java、C#、VB等就可以开始阅读本书。不过由于当中涉及到比较复杂的算法知识,需要读者有一定的数学修养和逻辑思维能力,否则可能书籍的后半部分阅读起来会比较吃力。
事实上,任何有难度的知识和技巧,都不是那么容易被掌握的。我尽管已经朝着通俗易懂的方向努力,可有些数据结构,特别是经典算法,是几代科学家的智慧结晶,因此要掌握它们还是需要读者的全力投入。
美国畅销书《如何阅读一本书》中提到“阅读可以是一件主动的事,阅读越主动,效果越好。拿同样的书给背景相近的两个人阅读,一个人却比另一个人从书中得到了更多,这是因为,首先在于这人的主动,其次,在于他在阅读中的每一种活动都参与了更多的技巧。这两件事是息息相关的。阅读是一个复杂的活动,就跟写作一样,包含了大量不同的活动。要达成良好的阅读,这些活动都是不可或缺的。一个人越能良好运作这些活动,阅读的效果也就越好。”
我当然希望读者在阅读本书后收获巨大,但这显然是一厢情愿。要想获得更多,您可能也需要付出类似我写作一样的力气来阅读,例如摘抄文字、眉批心得、稿纸演算、代码输入电脑,以及您自己在编程工作中的运用等。这些相应活动的执行,将会使您得到巨大的收获。
本书是用C语言编写,基于C90(ISO C)的标准。读者可以选择任何一款基于C90标准的C语言开发工具或更高版本的开发工具来学习本书中的代码。
本人一直习惯于用Visual.Studio2008作为开发工具,因此在写作此书时,也是用此工具的Visual.C++来编译调试代码,一切都相安无事,但写作完成后,考虑到不同读者应用开发工具的习惯不同,最终在编辑的建议下,决定提供一份可在C90标准的C语言开发环境中编译通过的代码,结果发现错误百出。例如C90标准的注释要求是“/*注释文字*/”而不允许是“//注释文字”:要求变量声明必须要在函数的最前面,只能是“inti;for(i=0;i出于为了让代码可以在低端编译环境通过的考虑,牺牲一些代码的简捷性和优雅性也是无可奈何和必要的。最终我将书中全部代码都改成C90标准的代码。
C语言初学者可能会因为刚接触编程语言,特别是对指针的理解不深,而担心阅读困难。我个人感觉,单纯学习指针是很难理解它的真正用途和好处,而通过学习数据结构,特别是像链式存储结构在各种结构算法中的运用,反而可以让读者进一步的理解指针的优越之处。从这个角度说,数据结构的学习可以反过来加强读者对C语言,特别是指针概念的理解。
C语言是一门古老的高级语言,它的应用范围非常广泛,因此我选择它作为本书的算法展示语言。如果读者之前学过它,那么阅读本书就不存在语言障碍。懂得C++语言的读者,同样也不会有任何语言上的问题。
像掌握Java、C#、VB等面向对象语言的读者,当面对书中大量的C语言式的结构(struct)声明和针对结构的参数传递的代码时,都可以理解为是类的定义和由类生成对象的传递。尽管的确存在差异,但是并不影响整体对数据结构知识和算法原理的理解。
我个人感觉,哪怕是对C语言不熟悉,也不妨利用学习数据结构的机会,学习一下C语言的编程方法,这对于将来应用其他高级语言也是有很大帮助的。
不是一个人在战斗
首先要感谢我的妻子李秀芳对我写作本书期间的全力支持,我辞职写作,没有她精神上的理解鼓励和生活上的悉心照顾,是不可能走出这一步并顺利完成书稿的。我们的儿子程晟涵如今已经三周岁,我是在他每日的欢声笑语和哭哭啼啼中进行每一章节的构思和写作,希望他可以茁壮成长。我的父母已经年迈,他们为我的全职创作也甚为担心和忧虑,这里也要说一声抱歉。
本人数据结构的知识,是源自清华大学出版社出版的《数据结构(C语言版)》(严蔚敏、吴伟民编着)一书,严老师和吴老师算是我在数据结构方面的启蒙老师,本书的不少内容和代码也是参考了此书。机械工业出版社的《算法导论》对于本人的算法知识提高帮助很大,写作中也大量吸收了书中的精华。写作过程中,本人购买和借阅了与数据结构相关的大量书籍,详细书目见附录。没有前辈的贡献,就没有本书的出版,也希望本书能成为这些书籍的前期读物。在此向这些图书作者表示衷心的感谢。
仅有作者是不可能完成图书的出版的,本人要非常感谢清华大学出版社的朋友们,他们是本书的最初读者,也是协助本人将此书由毛糙变精良的最有力帮手。
大家好!我是《大话设计模式》(2008年初出版)的作者,三年来,承蒙广大读者的厚爱,《大话设计模式》取得了较大的成功。仅在当当网,截止本文写作时,就已经有1073次评论,705次5星评价,位居五星图书榜计算机/网络类的累计总榜第二名。此书已经成为国内原创计算机类图书最畅销的书籍之一。
对于这样一个自己喜欢做、可以做得好,而且已经得到了市场广泛认可,为很多朋友提供帮助的事情,我没有理由不去继续做下去。这就是我准备再写书的原因。
我曾做过调查,数据结构的学习者大多都有这样的感慨:数据结构很重要,一定要学好,但数据结构比较抽象,有些算法理解起来很困难,学得很累。可我更希望传达这样的信息:数据结构非常有趣,很多算法是智慧的结晶,学习它是去感受计算机编程技术的魅力,在理解掌握它的同时,整个过程都是一种愉悦的精神感受,而非枯燥乏味的一门课程。因此我决定写作一本关于数据结构有趣的书。
不过现实总比理想来得更“现实”。要想把书写好,谈何容易,我需要突破很多困难……嗐!不管如何,现在您看到了本书,那就说明我已经克服了困难战胜了自己。希望您可以喜欢上这本书。

本书的定位就是一本适合读者自学数据结构的书籍,它有区别于教材,希望给大家另一种阅读体验。
通常讲解数据结构的图书都是以教材的方式呈现。在写作前,我购买或在图书馆借阅了十几本非常好的数据结构相关教材用来为写作本书做准备。但经过认真阅读后,我发现,它们大多不是一本好的“自学读物”。
我没有轻视这些好书的意思,不过教材和自学读物,所面向的读者是完全不同的。
好的教材应该是提纲挈领、重点突出,一定要留出思考的空间,否则就没必要再听老师上课了。很多内容的讲解是由老师在课堂完成,教材中有练习、课后习题、思考题等,这些大多可以通过老师来解答。比如我们中学时的语文、数学课本,很薄的一本书通常要用一学期、甚至一年的时间来学习,这就是因为它们是教材而不是自学读物。如果是小说,可能一两天就读完了。
好的自学读物的目标是让初学者“独自”全盘掌握知识,需要强调“独自”一词,这就说明读者在阅读时,是完全依靠自己的力量来向未知发出挑战。因此书中内容,要么不写,写了就应该写透。如果读者在阅读时总是疑惑重重,那么这本书就有很大的问题了。
我也就是在基于这样的认识,决心将《大话数据结构》真正写成一本关于数据结构和算法的自学读物来展开写作的。

第1章 数据结构绪论
1.1 开场白
1.2 你数据结构怎么学的?
1.3 数据结构起源
1.4 基本概念和术语
1.4.1 数据
1.4.2 数据元素
1.4.3 数据项
1.4.4 数据对象
1.4.5 数据结构
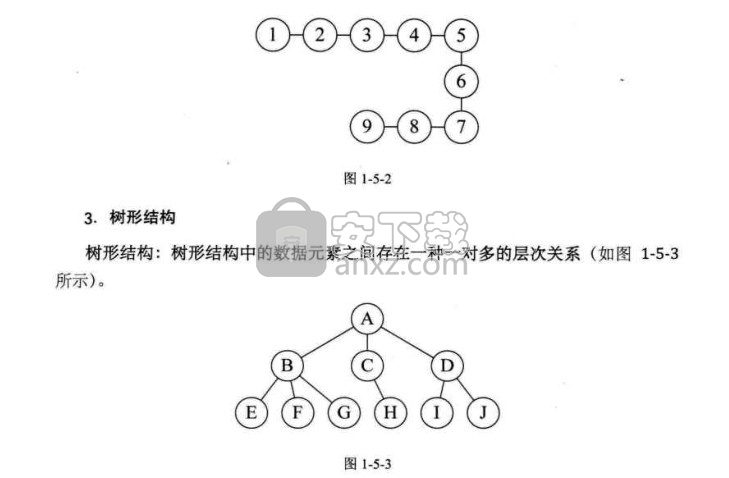
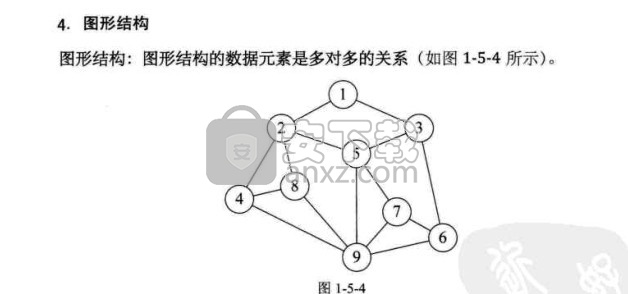
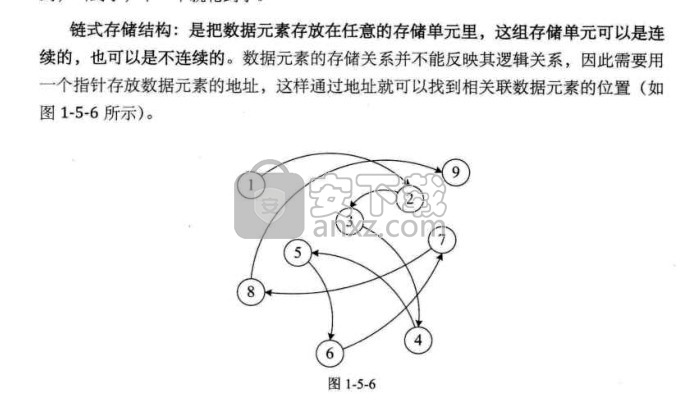
1.5 逻辑结构与物理结构
1.5.1 逻辑结构
1.5.2 物理结构
1.6 抽象数据类型
1.6.1 数据类型
1.6.2 抽象数据类型
1.7 总结回顾
1.8 结尾语
第2章 算法
2.1 开场白
2.2 数据结构与算法关系
2.3 两种算法的比较
2.4 算法定义
2.5 算法的特性
2.5.1 输入输出
2.5.2 有穷性
2.5.3 确定性
2.5.4 可行性
2.6 算法设计的要求
2.6.1 正确性
2.6.2 可读性
2.6.3 健壮性
2.6.4 时间效率高和存储量低
2.7 算法效率的度量方法
2.7.1 事后统计方法
2.7.2 事前分析估算方法
2.8 函数的渐近增长
2.9 算法时间复杂度
2.9.1 算法时间复杂度定义
2.9.2 推导大O阶方法
2.9.3 常数阶
2.9.4 线性阶
2.9.5 对数阶
2.9.6 平方阶
2.10 常见的时间复杂度
2.11 最坏情况与平均情况
2.12 算法空间复杂度
2.13 总结回顾
2.14 结尾语
第3章 线性表
3.1 开场白
3.2 线性表的定义
3.3 线性表的抽象数据类型
3.4 线性表的顺序存储结构
3.4.1 顺序存储定义
3.4.2 顺序存储方式
3.4.3 数据长度与线性表长度区别
3.4.4 地址计算方法
3.5 顺序存储结构的插入与删除
3.5.1 获得元素操作
3.5.2 插入操作
3.5.3 删除操作
3.5.4 线性表顺序存储结构的优缺点
3.6 线性表的链式存储结构
3.6.1 顺序存储结构不足的解决办法
3.6.2 线性表链式存储结构定义
3.6.3 头指针与头结点的异同
3.6.4 线性表链式存储结构代码描述
3.7 单链表的读取
3.8 单链表的插入与删除
3.8.1 单链表的插入
3.8.2 单链表的删除
3.9 单链表的整表创建
3.10 单链表的整表删除
3.11 单链表结构与顺序存储结构优缺点
3.12 静态链表
3.12.1 静态链表的插入操作
3.12.2 静态链表的删除操作
3.12.3 静态链表优缺点
3.13 循环链表
3.14 双向链表
3.15 总结回顾
3.16 结尾语
第4章 栈与队列
4.1 开场白
4.2 栈的定义
4.2.1 栈的定义
4.2.2 进栈出栈变化形式
4.3 栈的抽象数据类型
4.4 栈的顺序存储结构及实现
4.4.1 栈的顺序存储结构
4.4.2 栈的顺序存储结构进栈操作
4.4.3 栈的顺序存储结构出栈操作
4.5 两栈共享空间
4.6 栈的链式存储结构及实现
4.6.1 栈的链式存储结构
4.6.2 栈的链式存储结构进栈操作
4.6.3 栈的链式存储结构出栈操作
4.7 栈的作用
4.8 栈的应用--递归
4.8.1 斐波那契数列实现
4.8.2 递归定义
4.9 栈的应用--四则运算表达式求值
4.9.1 后缀(逆波兰)表示法定义
4.9.2 后缀表达式计算结果
4.9.3 中缀表达式转后缀表达式
4.10 队列的定义
4.11 队列的抽象数据类型
4.12 循环队列
4.12.1 队列顺序存储的不足
4.12.2 循环队列定义
4.13 队列的链式存储结构及实现
4.13.1 队列链式存储结构入队操作
4.13.2 队列链式存储结构出队操作
4.14 总结回顾
4.15 结尾语
第5章 串
5.1开场白
05.2 串的定义
5.3 串的比较
5.4 串的抽象数据类型
5.5 串的存储结构
5.5.1 串的顺序存储结构
5.5.2 串的链式存储结构
5.6 朴素的模式匹配算法
5.7 KMP模式匹配算法
5.7.1 KMP模式匹配算法原理
5.7.2 next数组值推导
5.7.3 KMP模式匹配算法实现
5.7.4 KMP模式匹配算法改进
5.7.5 nextval数组值推导
5.8 总结回顾
5.9 结尾语
第6章 树
6.1 开场白
6.2 树的定义
6.2.1 结点分类
6.2.2 结点间关系
6.2.3 树的其他相关概念
6.3 树的抽象数据类型
6.4 树的存储结构
6.4.1 双亲表示法
6.4.2 孩子表示法
6.4.3 孩子兄弟表示法
6.5 二叉树的定义
6.5.1 二叉树特点
6.5.2 特殊二叉树
6.6 二叉树的性质
6.6.1 二叉树性质1
6.6.2 二叉树性质2
6.6.3 二叉树性质3
6.6.4 二叉树性质4
6.6.5 二叉树性质5
6.7 二叉树的存储结构
6.7.1 二叉树顺序存储结构
6.7.2 二叉链表
6.8 遍历二叉树
6.8.1 二叉树遍历原理
6.8.2 二叉树遍历方法
6.8.3 前序遍历算法
6.8.4 中序遍历算法
6.8.5 后序遍历算法
6.8.6 推导遍历结果
6.9 二叉树的建立
6.10 线索二叉树
6.10.1 线索二叉树原理
6.10.2 线索二叉树结构实现
6.11 树、森林与二叉树的转换
6.11.1 树转换为二叉树
6.11.2 森林转换为二叉树
6.11.3 二叉树转换为树
6.11.4 二叉树转换为森林
6.11.5 树与森林的遍历
6.12 赫夫曼树及其应用
6.12.1 赫夫曼树
6.12.2 赫夫曼树定义与原理
6.12.3 赫夫曼编码
6.13 总结回顾
6.14 结尾语
第7章 图
7.1 开场白
7.2 图的定义
7.2.1 各种图定义
7.2.2 图的顶点与边间关系
7.2.3 连通图相关术语
7.2.4 图的定义与术语总结
7.3 图的抽象数据类型
7.4 图的存储结构
7.4.1 邻接矩阵
7.4.2 邻接表
7.4.3 十字链表
7.4.4 邻接多重表
7.4.5 边集数组
7.5 图的遍历
7.5.1 深度优先遍历
7.5.2 广度优先遍历
7.6 最小生成树
7.6.1 普里姆(Prim)算法
7.6.2 克鲁斯卡尔(Kruskal)算法
7.7 最短路径
7.7.1 迪杰斯特拉(Dijkstra)算法
7.7.2 弗洛伊德(Floyd)算法
7.8 拓扑排序
7.8.1 拓扑排序介绍
7.8.2 拓扑排序算法
7.9 关键路径
7.9.1 关键路径算法原理
7.9.2 关键路径算法
7.10 总结回顾
7.11 结尾语
第8章 查找
8.1 开场白
8.2 查找概论
8.3 顺序表查找
8.3.1 顺序表查找算法
8.3.2 顺序表查找优化
8.4 有序表查找
8.4.1 折半查找
8.4.2 插值查找
8.4.3 斐波那契查找
8.5 线性索引查找
8.5.1 稠密索引
8.5.2 分块索引
8.5.3 倒排索引
8.6 二叉排序树
8.6.1 二叉排序树查找操作
8.6.2 二叉排序树插入操作
8.6.3 二叉排序树删除操作
8.6.4 二叉排序树总结
8.7 平衡二叉树(AVL树)
8.7.1 平衡二叉树实现原理
8.7.2 平衡二叉树实现算法
8.8 多路查找树(B树)
8.8.1 2-3树
8.8.2 2-3-4树
8.8.3 B树
8.8.4 B+树
8.9 散列表查找(哈希表)概述
8.9.1 散列表查找定义
8.9.2 散列表查找步骤
8.10 散列函数的构造方法
8.10.1 直接定址法
8.10.2 数字分析法
8.10.3 平方取中法
8.10.4 折叠法
8.10.5 除留余数法
8.10.6 随机数法
8.11 处理散列冲突的方法
8.11.1 开放定址法
8.11.2 再散列函数法
8.11.3 链地址法
8.11.4 公共溢出区法
8.12 散列表查找实现
8.12.1 散列表查找算法实现
8.12.2 散列表查找性能分析
8.13 总结回顾
8.14 结尾语
第9章 排序
9.1 开场白
9.2 排序的基本概念与分类
9.2.1 排序的稳定性
9.2.2 内排序与外排序
9.2.3 排序用到的结构与函数
9.3 冒泡排序
9.3.1 最简单排序实现
9.3.2 冒泡排序算法
9.3.3 冒泡排序优化
9.3.4 冒泡排序复杂度分析
9.4 简单选择排序
9.4.1 简单选择排序算法
9.4.2 简单选择排序复杂度分析
9.5 直接插入排序
9.5.1 直接插入排序算法
9.5.2 直接插入排序复杂度分析
9.6 希尔排序
9.6.1 希尔排序原理
9.6.2 希尔排序算法
9.6.3 希尔排序复杂度分析
9.7 堆 排 序
9.7.1 堆排序算法
9.7.2 堆排序复杂度分析
9.8 归并排序
9.8.1 归并排序算法
9.8.2 归并排序复杂度分析
9.8.3 非递归实现归并排序
9.9 快速排序
9.9.1 快速排序算法
9.9.2 快速排序复杂度分析
9.9.3 快速排序优化
1.优化选取枢轴
2.优化不必要的交换
3.优化小数组时的排序方案
4.优化递归操作
9.10 总结回顾
9.11 结尾语

方法一:
1、下载并解压,得出pdf文件
2、如果打不开本文件,可以到本站下载阅读工具
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读
方法二:
1、在手机里下载3322软件站中的阅读器和百度网盘
2、直接将pdf传输到百度网盘
3、用阅读器打开即可阅读
数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。
比如我们现在常用的搜索引擎,一般会有网页、MP3、图片、视频等分类。MP3就是声音数据,图片当然是图像数据,视频就不用说了,而网页其实指的就是全部数据的搜索,包括最重要的数字和字符等文字数据。
也就是说,我们这里说的数据,其实就是符号,而且这些符号必须具备两个前提:
可以输入到计算机中。
能被计算机程序处理。
对于整型、实型等数值类型,可以进行数值计算。
对于字符数据类型,就需要进行非数值的处理。而声音、图像、视频等其实是可以通过编码的手段变成字符数据来处理的。
建议本书的研读方法为:
1.复习C语言的基础知识。如果你掌握的是别的语言也不要紧,适当了解一些C语言和你掌握的编程语言的语法差异还是有必要的。甚至将本书代码改造成另一种语言本身就是一种非常好的学习方法。
2.阅读第一遍时,建议从头至尾进行。如果你对前面的知识有足够了解,当然可以跳过直接阅读后面的章节。不过若要学习一门完整的知识并形成体系。通读本书,还是最好的学习方法。
3.阅读时,摘抄是非常好的习惯。“最淡的墨水也胜于最强的记忆!”有不少读者会认为摘抄了将来也不会再去看,有什么必要,但其实在写字的过程就是大脑学习的过程,写字在减缓你阅读的速度,从而让你更好地消化阅读的内容。相信大家都能理解,“囫囵吞枣”和“慢慢品味”的差异,学习同样如此。
4.阅读每一章时,特别是在阅读算法的推导过程时,一定要在电脑中运行代码(本书源码的下载地址可以到http://cj723.cnblogs.com中的《大话数据结构相关主题》中找到),了解代码的运行过程。本书的很多算法都做到了逐行讲解,但单纯阅读可能真的很难达到理解的程度(这是纸质书无法克服的缺陷),需要你通过开发工具调试,并设置断点和逐行执行,并参照书中的讲解,观察变量的变化情况来理解算法的编写原理。
5.阅读完每一章时,一定要在理解基础上记忆一些关键东西。最佳的效果就是你可以不看书也做到一点不错地默写出相关算法。
6.阅读完每一章时,一定要适当练习。本书没有提供练习题,但市场上相关的数据结构习题集比比皆是,可以选择尝试。另外互联网上也可以获得足够的习题来给你练习。练习的目的是为了检测自己是否真的完全理解了书中的内容。事实上很多时候,阅读中的人们只是自我感觉理解,而并非真正的明白。
7.学习不可能一蹴而就,数据结构和算法如果通过一本书就可以掌握,那本身就是笑话。本书附录提供了本书写作时的参考书目,基本都是最优秀的数据结构或相关的中文书籍各有侧重,建议大家可以适当地阅读。
8.在之后的编程学习和工作中,尽量把已经学到的数据结构和算法知识运用到现实开发中。遗忘时翻阅本书回顾相关内容,最终达到精通数据结构和相关算法的境界。
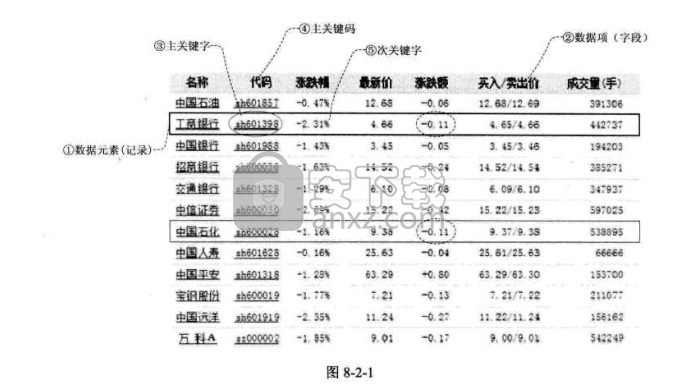
数据元素:是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理。
也被称为记录。比如,在人类中,什么是数据元素呀?当然是人了。畜类呢?哈,牛、马、羊、鸡、猪、狗等动物当然就是禽类的数据元素。
数据项:一个数据元素可以由若干个数据项组成。
比如人这样的数据元素,可以有眼、耳、鼻嘴、手、脚这些数据项,也可以有姓名、年龄、性别、出生地址、联系电话等数据项,具体有哪些数据项,要视你做的系统来决定。
数据项是数据不可分割的最小单位。在数据结构这门课程中,我们把数据项定义为最小单位,是有助于我们更好地解决问题所以,记住了,数据项是数据的最小单位。但真正讨论问题时,数据元素才是数据结构中建立数据模型的着眼点。就像我们讨论一部电影时,是讨论这部电影角色这样的“数据元素”,而不是针对这个角色的姓名或者年龄这样的“数据项”去研究分析。
只要你打开电脑,就会涉及到查找技术。如炒股软件中查股票信息、硬盘文件中找照片、在光盘中搜DVD,甚至玩游戏时在内存中查找攻击力、魅力值等数据修改用来作弊等,都要涉及到查找。当然,在互联网上查找信息就更加是家常便饭。所有这些需要被查的数据所在的集合,我给它一个统称叫查找表。
出版社: 清华大学出版社
ISBN:9787302255659
版次:1
商品编码:10663703
品牌:清华大学
包装:平装
开本:16开
出版时间:2011-06-01
用纸:胶版纸
页数:439
字数:662000
正文语种:中文
极速pdf阅读器 电子阅读9.75 MB3.0.0.3030
详情悦书pdf阅读器 电子阅读114.28 MB4.3.1.0
详情Effie写作软件 电子阅读64.19 MBv3.8.3
详情ReadBook阅读器 电子阅读3.85 MBv1.63 (内置激活码)
详情PDF-XChange Pro 5.0.273.2 中文精简版 电子阅读36.00 MB
详情neat reader 电子阅读74.2 MBv6.0.4 附破解方法
详情熊熊小说下载器 1.3 电子阅读1.00 MB
详情文电通PDF Gold v9.10 简体中文 电子阅读30.00 MB
详情IceCream Ebook Reader Pro(电子书阅读器) 电子阅读27.0 MBv4.53
详情Adobe Acrobat 7.0 pro中文专业 电子阅读210 MB附安装程序(含序列号)
详情Adobe Acrobat XI Pro 单文件全能版 电子阅读33.00 MB
详情adobe acrobat pro dc 2018绿色便携版 电子阅读440 MBv18.011.20040
详情Chm电子书批量反编译器(ChmDecompiler) 3.66 电子阅读2.07 MB
详情语音朗读翻译王 2.1 电子阅读0.54 MB
详情PDF阅读编辑打印工具 PDF-XChange View Pro 2.5.322.9 中文增强版 电子阅读56.00 MB
详情ABBYY Lingvo X6(多功能电子词典) 电子阅读1587 MBv16.2.2
详情adobe acrobat pro dc 2017 电子阅读758 MBv17.009.20044 中文免费版
详情PDF Annotator 2.0.0.250 汉化 电子阅读17.00 MB
详情adobe acrobat pro dc 2018中文 电子阅读599 MBv18.009.20050
详情nitro pro enterprise 12 电子阅读250 MBv12.0.0.112 64位32位版
详情PDF阅读器 Adobe Acrobat XI Pro 珍藏版 电子阅读259.00 MB
详情CAJViewer 7.2精简绿色版 CAJ、NH、KDH阅读器 电子阅读8.00 MB
详情Adobe Acrobat XI Pro 单文件全能版 电子阅读33.00 MB
详情福昕PDF阅读器 v8.1.0.1013 汉化增强版 电子阅读21.00 MB
详情adobe reader 10.0中文官方版 电子阅读53.9 MBv10.0.3 免费版
详情无限制pdg阅读器 电子阅读0.59 MB
详情Adobe Acrobat 7.0 pro中文专业 电子阅读210 MB附安装程序(含序列号)
详情大话数据结构 电子阅读37.64 MBpdf扫描版
详情全世界3000份报纸天天读 3.15.291 电子阅读3.00 MB
详情Djvu格式文件阅读器 1.0 绿色版 电子阅读0.53 MB
详情CAJViewer(caj阅读器) 电子阅读263.43 MBv7.3.141 官方最新版
详情adobe acrobat pro dc 2018中文 电子阅读599 MBv18.009.20050
详情adobe acrobat 9 pro 完整版 电子阅读618 MB附安装程序
详情adobe acrobat xi pro 电子阅读722 MBv11.0.10 中文版
详情方正 Apabi Reader 4.2.0 简体中文版 电子阅读22.00 MB
详情迷你PDG阅读器 电子阅读1.00 MB
详情Neat Reader(ePub阅读器) 电子阅读33.8 MBv3.2.1 绿色版
详情xps viewer(xps阅读器) 电子阅读1.1 MBv1.1.0 官方版
详情adobe acrobat pro dc 2019中文 电子阅读1106 MBv2019.008.20071 完整版
详情adobe reader xi 官方简体中文版 电子阅读53.9 MBv11.0.18 免费版
详情福昕PDF阅读器 Foxit Reader 电子阅读67.56 MBv10.0.130.36332 中文版
详情Balabolka(语音阅读器) 电子阅读22.71 MBv2.15.0.805
详情CAJViewer(caj阅读器) 电子阅读263.43 MBv7.3.141 官方最新版
详情极速pdf阅读器 电子阅读9.75 MB3.0.0.3030
详情MailsDaddy Free MSG Viewer(MSG文件阅读器) 电子阅读3.88 MBv1.0 官方版
详情超小快速简洁PDF阅读器 SumatraPDF v3.4.0.13798 中文版 电子阅读11.97 MBv3.4.0.13798
详情福昕PDF阅读器 v8.1.0.1013 汉化增强版 电子阅读21.00 MB
详情Adobe Acrobat XI Pro 单文件全能版 电子阅读33.00 MB
详情TXT小说下载器 绿色版 电子阅读2.00 MB
详情方正 Apabi Reader 4.2.0 简体中文版 电子阅读22.00 MB
详情





























