SPSS Modeler(数据挖掘)
v18.0 中文大小:1864 MB 更新:2023/03/18
类别:信息管理系统:WinXP, Win7, Win8, Win10, WinAll
分类分类
大小:1864 MB 更新:2023/03/18
类别:信息管理系统:WinXP, Win7, Win8, Win10, WinAll
IBMSPSS
Modeler提供数据数据分析功能,可以帮助用户建立模型挖掘数据,当用户需要分析工程项目,需要分析商业项目的时候就可以通过这款软件建立数据模型分析,在可视化的模型界面查看分析数据,为后期优化项目提供帮助,软件支持建模功能,可以直接使用软件提供的自动分类器、自动数值、自动聚类、决策列表、C5.0、回归、主成分分析因子、特征选择、Logistic、Apriori、Carma、序列等功能设计模型,也可以选择从数据库建立模型,也支持创建图形,可以添加图形板、散点图、多重散点图、时间散点图、分布、直方图、集合、网络、评估、地图可视化等内容,如果你需要这款软件就下载吧!

1、文本分析
借助可定制 的特定行业文本分析包,您可以对正确的上下文里的除首 字母缩写、表情符号和俚语之外的相关术语和词组进行分 析。交互式图表可帮助您探索和显示文本数据和模式,以 便进行快速分析。
2、实体分析
借助软件 的实体分析功能,您可非常轻松高效地 将身份、行为和行动数据与各自的实体实时或批量关联起来。 您还可适时合并记录或将它们分离开来。结果会怎样呢?您 的组织将具有可帮助提高模型质量的关联企业数据。
3、社交网络分析
软件 可提供相关社交网络分析功能,将与关系有 关的信息转为显示个人和团队的社会行为的关键业绩指标。 您可以利用这些指标来识别影响网络中他人行为的社交领导 者。结合这些结果与其他措施,您可以创建全面的个人资料 文件,并以此作为您的预测性模型的基础。
3、一系列模型及算法
分类算法-根据历史数据和技术进行预测。分段算法-利用自动聚类、异常检测和聚类神经网络技术 将工作人员进行分组或检测不寻常的模式。关联算法-发现先验、CARMA 和序列关联性的关联、链 接或序列。时间系列和预测-随着时间的推移,利用统计建模技术生成一个或多个系列的预测。可扩展性与 R 编程语言-应用转型,用脚本进行分析, 并用 R 编程语言汇总或生成文本和图形输出。
4、数据准备和操作
软件使数据准备自动化,以简化流程并帮助您确 保您的数据格式为便于分析的最好格式。自动化任务包括进 行分析数据和识别修复工具,筛选字段,必要时派生新属性, 并通过智能筛选技术提高性能。
5、自动数据建模
借助软件的自动建模功能,非分析师人员无需 专业技能即可迅速构建准确的模型。此外,先进的预测建 模功能可支持专业分析人员创建最复杂的流。
6、地理空间分析
借助软件,您可探索与某个位置有关的各个数 据元素之间的关系并对您的数据进行地理空间分析,以发掘在图表或表格中不可见的洞察力。通过空间挖掘,您可 利用 ESRI shape file 文件轻松挖掘地理空间数据。通过分 析空间数据和非空间数据,可以提高整个模型的准确性, 且您可以获取对人员和事件的更深入洞察力。
IBM SPSS Modeler在此次发行版中增加了下列功能
建模器客户机现在可于Mac操作系统上使用。 SPSS Modeler Professional和 Premium现在支持Mac操作系统。
时间序列节点
新“时间序列节点可用。新节点和前发行版中的“时间序列”节点相似,但它通过嵌入或远程 IBM SPSS Analytic Server来处理大数据和在输出查看器中显示产生的模型。还提供基于新“时间序列节点的新“流式时间序列”节点。
注:本发行版中已不推荐旧“时间序列”、“流式时间序列”和“时间间隔”节点;但是,在所有现有流中仍然支持其功能。
扩展集线器
添加了新“扩展集线器”(可从 IBM SPSS Modeler Client中的扩展>扩展集线器访问)。“扩展集线器”是通过 GitHub上的 IBM SPSS Predictive Analytics搜索、下载和安装扩展的界面。
自定义对话框构建程序
“自定义对话框构建程序”中进行了多项改进,并添加了多项增强功能。
建模器服务器上的 Python Spark
在第17.1版中,针对 IBM SPSS Analytic Server运行时,添加了对 Python Spark的支持(以前只支持R)。现在,还支持 SPSS Modeler Server.
1、首先打开第一个文件夹执行安装“1 SPSS_Modeler_18(bit64)”
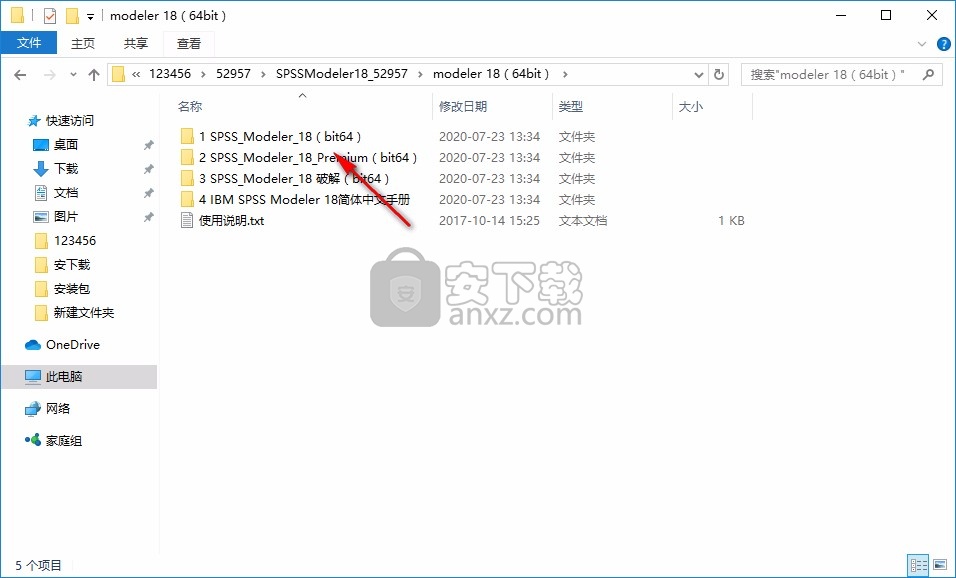
2、找到setup.exe双击启动安装
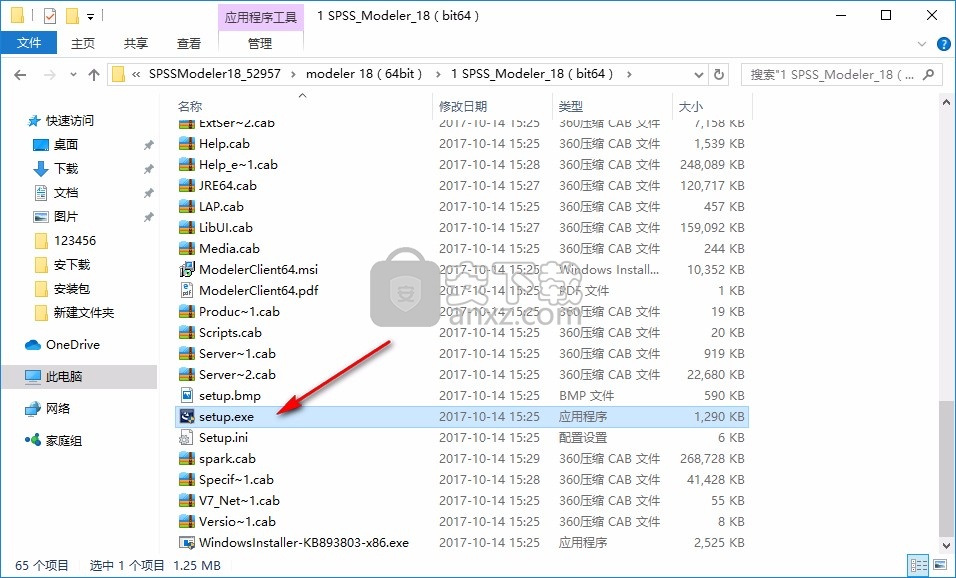
3、这里是软件的安装界面,点击下一步
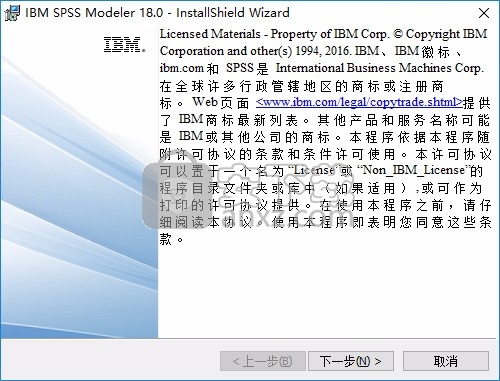
4、提示软件的协议内容,点击下一步
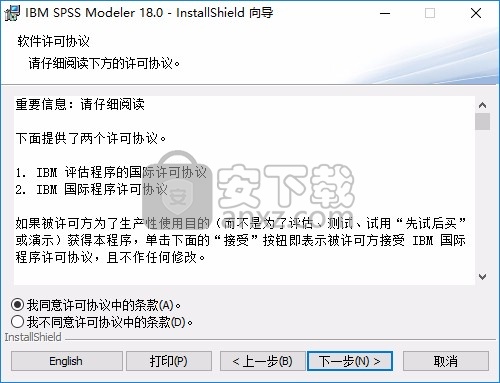
5、设置软件的安装地址,您可以默认当前的地址,也可以修改地址
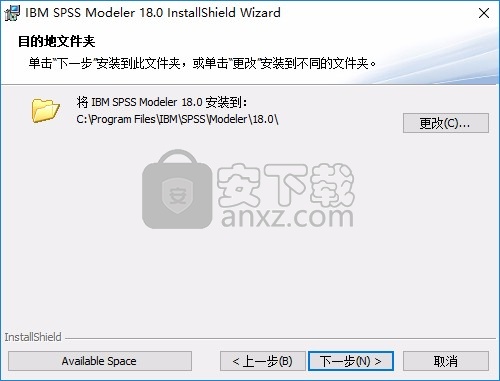
6、小编将地址修改为E盘,点击下一步
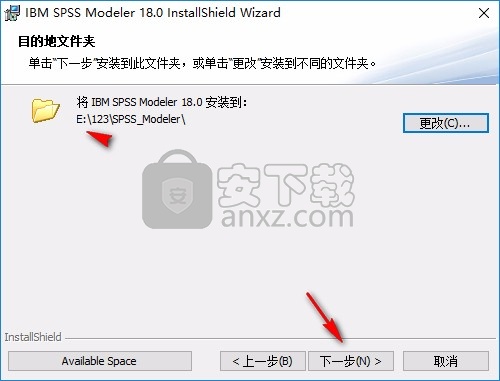
7、提示安装准备界面,点击安装
8、SPSS_Modeler软件已经安装结束,点击完成,不要打开软件
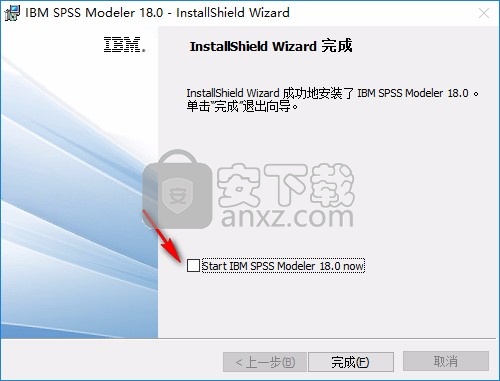
9、继续打开第二个文件夹2 SPSS_Modeler_18_Premium(bit64),安装setup.exe
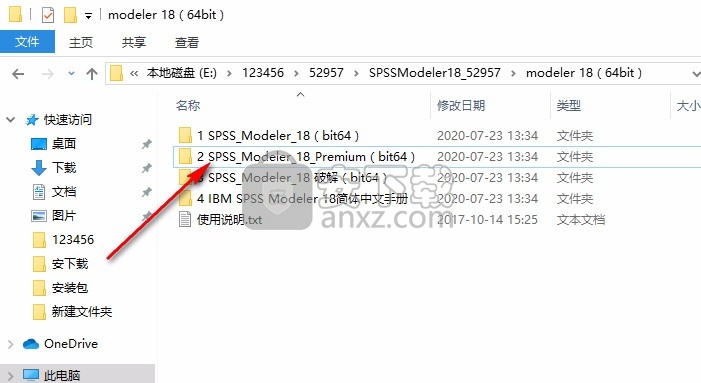
10、一直点击next安装,软件会自动找到你设置的安装地址,如果不正确就自己修改
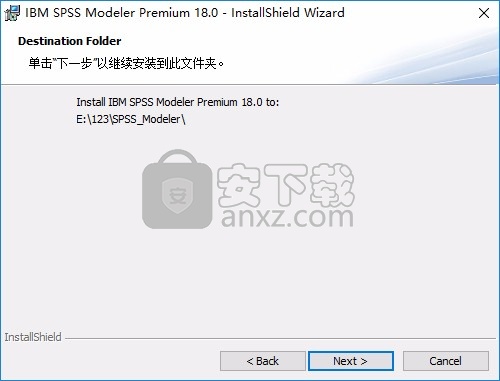
11、安装结束,点击finish结束安装
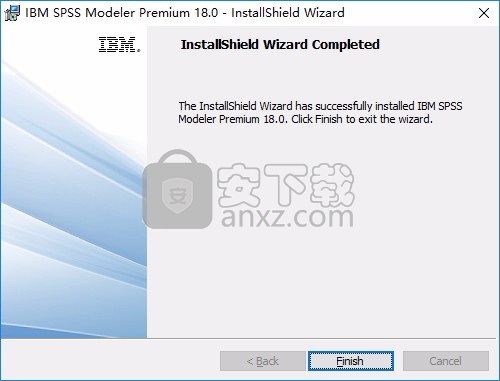
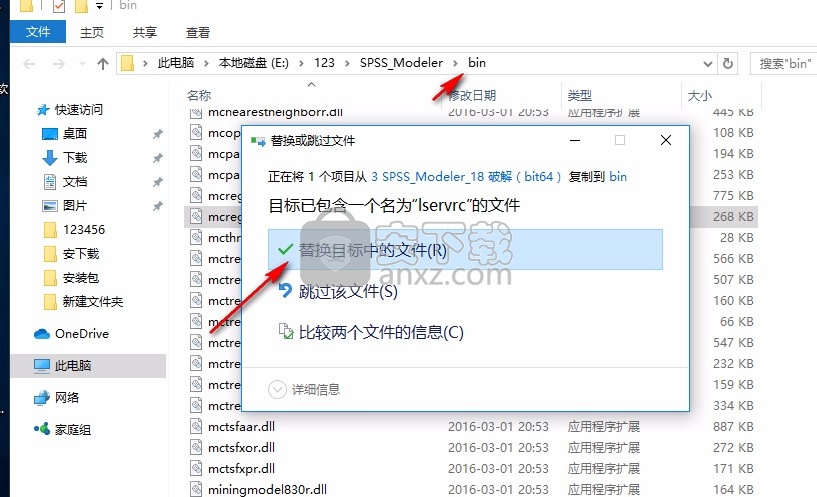
12、打开第三个文件夹3 SPSS_Modeler_18 (bit64),复制lservrc到安装地址替换
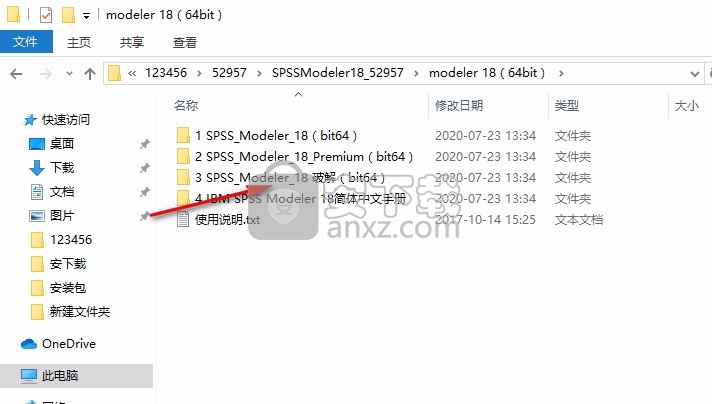
13、替换bin文件夹里面的内容,如果您没有修改安装地址,就复制到C:\Program Files\IBM\SPSS\Modeler\18.0\bin替换
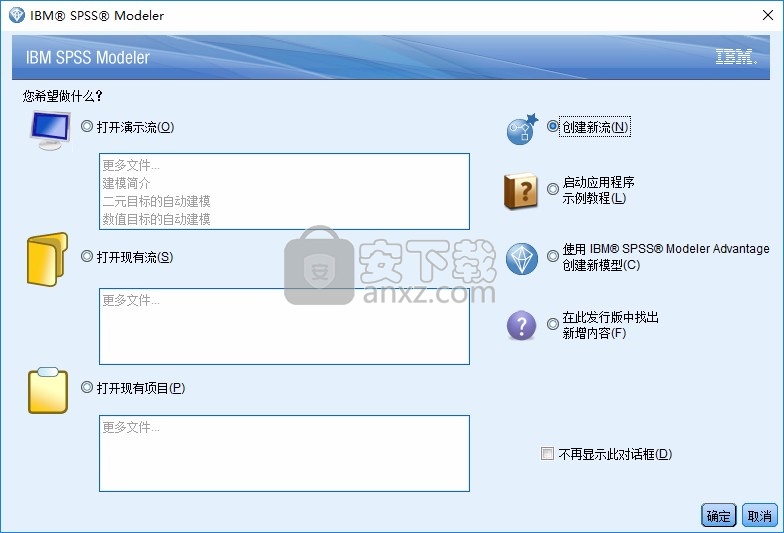
14、打开软件就可以正常使用,这里是新建项目的界面
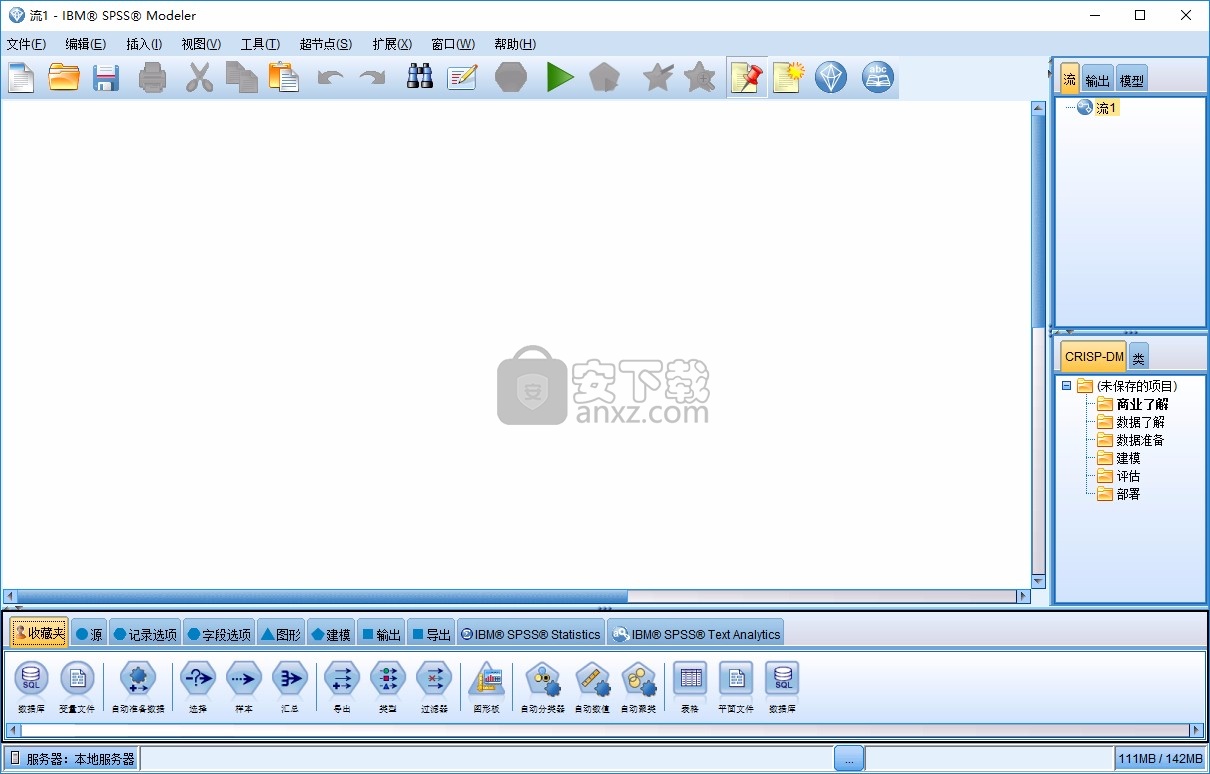
15、进入软件功能界面,如果你会使用就可以开始分析数据
流构建概述
使用 IBM® SPSS® Modeler 进行的数据挖掘重点关注通过一系列节点运行数据的过程,我们将这一过程称为流。这一系列节点代表要对数据执行的操作,而节点之间的链接指示数据流的方向。通常,您可以使用数据流将数据读入 IBM SPSS Modeler,通过一系列操作运行数据,然后将其发送至某个地方,如表格或查看器。
例如,假定您需要打开某个数据源、添加新字段、根据新字段中的值选择记录,然后在表中显示结果。在这种情况下,您的数据流应由以下四个节点组成:
“变量文件”节点,设置此节点后可以读取数据源中的数据。
导出节点,用于向数据集中添加计算的新字段。
选择节点,用于设置选择标准,以从数据流中排除某些记录。
表节点,用于在屏幕上显示操作结果。
将节点添加至流
可以通过多种方法将节点从节点选用板添加至流:
双击选用板中的节点。注:双击某个节点会自动将其连接到当前流。
将节点从选用板拖放到流工作区。
单击选用板中的节点,然后单击流工作区。
从 IBM® SPSS® Modeler 的“插入”菜单中选择合适的选项。
将节点添加至流工作区后,双击该节点可显示相应的对话框。可用选项取决于您要添加的节点的类型。有关对话框中特定控件的信息,请单击其帮助按钮。
除去节点
要从数据流中除去某个节点,请单击该节点并按 Delete 键,或者单击鼠标右键并从菜单中选择删除。
连接流中的节点
已添加到流工作区的节点在连接之前不会形成数据流。节点之间的连接指示数据从一项操作流向下一项操作的方向。连接节点以形成流的方法有以下几种:双击、使用鼠标中键或手动连接。
通过双击添加并连接节点
形成流的最简单的方法是双击选项板中的节点。此方法会自动将新节点连接到流工作区中的选定节点。例如,如果工作区包含一个“数据库”节点,则可以选中该节点,然后在选项板中双击下一个节点,如“导出”节点。此操作会自动将“导出”节点连接到现有的“数据库”节点。您可以重复此过程,直到到达终端节点(如“直方图”或“表”节点),这时所有新节点都将连接到上游最后一个非终端节点。
使用鼠标中键连接节点
在流工作区中,可以使用鼠标中键单击某个节点并将其拖到另一个节点。(如果鼠标没有中键,可以通过按住 Alt 键的同时使用鼠标从一个节点拖到另一个节点来模拟此操作。)
手动连接节点
如果没有鼠标中键并希望手动连接节点,您可以使用节点的弹出菜单将其连接到工作区已有的另一个节点。
1、右键单击选择连接的起始节点。这将打开节点菜单。
2、在菜单中单击连接。
3、此时,开始节点和光标处将同时显示连接图标。单击工作区中的第二个节点以连接这两个节点。
连接节点时,需要遵循以下几项规则。如果尝试进行以下任何一种连接,您将收到错误消息:
指向源节点的连接
发自终端节点的连接
超出节点的最大输入连接数
连接两个已连接的节点
循环(数据返回其从中流出的节点)
绕过流中的节点
如果绕过数据流中的某个节点,该节点的所有输入和输出连接都将替换为直接从其输入节点通向其输出节点的连接。如果该节点不同时具备输入连接和输出连接,则会删除该节点的所有连接,而不是更改路线。
例如,您可能有这样一个流,它导出一个新字段、过滤字段,然后研究直方图和表中的结果。如果还希望在过滤字段之前查看相同的数据图形和数据表,您可以在流中添加新的直方图节点和表节点,也可以绕过过滤节点。绕过“过滤”节点时,将直接通过“导出”节点连接到图形和表。“过滤”节点将从流中断开连接。
绕过节点
1、在流工作区中,使用鼠标中键双击要绕过的节点。或者,您还可使用 Alt+双击。
注:可以在“编辑”菜单中单击撤消或按 Ctrl+Z 撤消此操作。
节点的高速缓存选项
为优化流运行,可以在任何非终端节点上建立缓存。如果已在节点上建立了缓存,则在下一次运行数据流时流过节点的数据会充满缓存。从这时起,就会从缓存(存储在磁盘的临时目录中)而不是从数据源中读取数据了。
对于诸如排序、合并或汇总这样比较耗时的操作,缓存是最有用的。例如,假设已设置可从数据库中读取销售数据的源节点,和可按区域汇总销售数据的“汇总”节点。可以在“汇总”节点上建立缓存而不是在源节点上建立缓存,因为希望缓存存储的是已汇总的数据而不是整个数据集 。
注:源节点位置的缓存仅用于存储读入 IBM® SPSS® Modeler 的原始数据复本,在大多数情况下,它不会带来性能方面的提升。
对于已启用缓存的节点,会在右上角显示一个小的文档图标。当节点上的数据被缓存时,文档图标将变绿。
启用缓存
在流工作区中右键单击节点,然后在菜单中单击高速缓存。
在缓存子菜单中,单击启用。
可以通过右键单击节点,然后在缓存子菜单中单击禁用来关闭缓存。
数据库中的缓存节点
对于在数据库中运行的流,可于中游将数据缓存到数据库的临时表中而不是文件系统中。如果与 SQL 优化相组合,则此操作将使性能得到显着提高。例如,可以对合并多个表以创建数据挖掘视图的流的输出进行缓存并在需要时重新使用。通过为所有下游节点自动生成 SQL,性能可得到进一步的提高。
对长度超过 255 个字符的字符串使用数据库缓存时,应确保在缓存节点上游存在类型节点,并且读取了字段值,或者通过 options.cfg 文件中的 default_sql_string_length 参数来设置字符串长度。这样可以保证将临时表中的对应列设为正确宽度以适应字符串。
为利用数据库缓存,必须同时启用 SQL 优化和数据库缓存。注意,服务器上的优化设置将覆盖客户端上的优化设置。有关更多信息,请参阅设置流的优化选项主题。
如果已启用数据库缓存,则只需用右键单击任意非终端节点就可以缓存该点上的数据,并且在下次运行流时,可以直接在数据库中自动创建缓存。如果未启用数据库缓存或 SQL 优化,则会转而将缓存写入文件系统中。
注:下列数据库支持用于缓存的临时表:DB2、Netezza、Oracle、SQL Server 和 Teradata。其他数据库将使用标准表用于数据库缓存。可以针对特定数据库定制 SQL 代码 - 请与服务人员联系以获取帮助。
刷新高速缓存
节点上的白色文档图标指示其高速缓存为空。当高速缓存已满时,该文档图标将保持绿色不变。如果要替换高速缓存的内容,必须先刷新高速缓存,然后重新运行数据流以对其进行重新填充。
1、在流工作区中右键单击节点,然后在菜单中单击高速缓存。
2、在高速缓存子菜单中,单击刷新。
保存高速缓存
可以将高速缓存的内容保存为 IBM SPSS Statistics 数据文件 ( *.sav)。随后您可以将该文件作为高速缓存重新加载,也可以设置将该高速缓存文件用作其数据源的节点。此外,还可以加载其他工程中保存的高速缓存。
1、在流工作区中右键单击节点,然后在菜单中单击高速缓存。
2、在高速缓存子菜单中,单击保存高速缓存。
3、在“保存高速缓存”对话框中,浏览至要保存高速缓存文件的位置。
4、在“文件名”文本框中输入名称。
5、确保在“文件类型”列表中选中 *.sav,然后单击保存。
加载高速缓存
如果在将某个高速缓存文件从节点中删除之前已对其进行了保存,则可以重新加载该文件。
1、在流工作区中右键单击节点,然后在菜单中单击高速缓存。
2、在高速缓存子菜单中,单击加载高速缓存。
3、在“加载高速缓存”对话框中浏览至高速缓存文件所在位置,选中该文件,然后单击加载。
查看流操作消息
使用“流属性”对话框中的“消息”选项卡,可以轻松查看有关运行、优化和模型构建和评估所用时间等流操作的消息。该表还会报告错误消息。
查看流消息
1、在“文件”菜单中,单击流属性(或从管理器窗格中的“流”选项卡上选择流,右键单击并在弹出菜单中单击流属性)。
2、单击 消息 选项卡。
或者,在“工具”菜单中,单击:
流属性 > 消息
除有关流操作的消息之外,此处还报告错误消息。当流运行因错误而终止时,此对话框将在“消息”选项卡中打开,并显示错误消息。此外,出错节点将在流工作区中突出显示为红色。
如果在“用户选项”对话框中启用了 SQL 优化和日志选项,则还会显示有关生成的 SQL 的信息。
可以通过从保存按钮下拉列表(位于左侧“消息”选项卡的下方)中单击保存消息为流保存此处报告的消息。此外,也可以通过在“保存”按钮列表中单击清除所有消息清除给定流的所有消息。
请注意,CPU 时间是服务器进程使用 CPU 的时间长度。耗用时间是执行开始与执行结束之间的总时间,因此还包括传输文件和呈示输出等操作所耗用的时间。当流使用了多个 CPU(并行执行)时,CPU 时间可能会大于耗用时间。如果流完全推回到用作数据源的数据库中进行处理,那么 CPU 时间将为零。
有道云笔记 信息管理113.77 MB8.0.70
详情为知笔记 v0.1.103 信息管理61.33 MB0.1.103
详情Efficient Efficcess Pro(个人信息管理软件) 信息管理31.3 MBv5.60.555 免费版
详情originpro8中文 信息管理123 MB附安装教程
详情鸿飞日记本 2009 信息管理0.55 MB
详情竞价批量查排名 信息管理73.5 MBv2020.7.15 官方版
详情Scratchboard(信息组织管理软件) 信息管理17.1 MBv30.0
详情Fitness Manager(俱乐部管理软件) 信息管理52.1 MBv9.9.9.0
详情Abelssoft MyKeyFinder 2020 信息管理6.35 MBv9.2.40
详情nvivo 20中文 信息管理575 MBv20.2.0.426 附安装教程
详情GenoPro 2019(家谱和基因图创建工具) 信息管理8.2 MBv3.0.1.5 中文
详情Splunk Enterprise(数据分析软件) 信息管理149 MBv6.4.3 免费版
详情endnote x9.1中文版下载 信息管理107.0 MB附安装教程
详情超级便笺本 V2.5 绿色 信息管理0.5 MB
详情The Journal(日记软件) 信息管理30.1 MBv7.0
详情Statgraphics Centurion19(数据可视化分析软件) 信息管理188 MBv19.1.2 附激活教程
详情ibm spss amos 26 信息管理168 MB附安装教程
详情移盘检索精灵 4.2 信息管理1.00 MB
详情思维导图 The Brain 7.0.4.1 简体中文专业 信息管理19.00 MB
详情有道云笔记电脑版 4.0 去广告绿色版 信息管理13.00 MB
详情A+客户端(房源管理系统) 信息管理49.6 MBv1.0.95 官方版
详情endnote x9.1中文版下载 信息管理107.0 MB附安装教程
详情船讯网船舶动态查询系统 信息管理0 MB2020 官方版
详情网文快捕 (CyberArticle) v5.5 中文 信息管理22.00 MB
详情中兴zte td lte 信息管理18.9 MBv1.2.2.17 官方最新版
详情Canon IJ Scan Utility(多功能扫描仪管理工具) 信息管理61.55 MBv5.2 免费版
详情第二代居民身份证读卡软件 信息管理4.25 MBv2.7.5 官方版
详情ZKTeco居民身份证阅读软件 信息管理76.2 MBv2.0.0.62 标准通用版
详情noteexpress(文献管理软件) 信息管理82.7 MBv3.2.0.7350
详情初妆助手 信息管理43.4 MBv2.0.0.22 官方版
详情思维导图软件 XMind 8 Update 8 中文注册版 信息管理179.00 MB
详情鼠标连点器 信息管理32.4 MBV2.0 绿色版
详情Review Manager(meta分析与数据记录软件) 信息管理56.35 MBv5.3.5 免费版
详情用户名批量生成器 绿色版 信息管理2.00 MB
详情originpro 2021 信息管理527 MB附安装教程
详情个人电子书架 Calibre v3.28 简体中文版 信息管理55.00 MB
详情Text Statistics Analyzer(文本统计分析器) 信息管理1.72 MBv2.4 汉化特别版
详情网文快捕(CyberArticle) 信息管理11.5 MBv6.0
详情任务规划 EssentialPIM Pro 信息管理31.9 MBv8.54.0 中文注册版
详情Advanced Office Password Recovery(密码恢复工具) 信息管理42.85 MBv6.50 免费版(附带序列号)
详情畅邮(Dreammail Pro) 信息管理63.43 MBv6.5.0.6 官方版
详情剑鱼论坛系统 信息管理3.11 MBv3.5.0 官方版
详情Joplin(笔记记录与待办事项管理器) 信息管理180.27 MBv2.6.7
详情超级通讯王(SuperPIM) 1.94.621 正式注册版 信息管理0 MB
详情轻量级笔记 CintaNotes Pro 3.8.0 中文版 信息管理10.00 MB
详情网文任我存 1.6.0.2 多国语言注册版 信息管理2.18 MB
详情网文快捕 (CyberArticle) v5.5 中文 信息管理22.00 MB
详情中华通讯录 5.8.109 Build 注册版 信息管理3.00 MB
详情Snappy Fax 2000 V3.55.5.4 信息管理6.34 MB
详情友情强档 WinPIM 15.30.4331 中文绿色企业版 信息管理11.00 MB
详情