Screaming Frog SEO Spider(网络爬虫开发工具)
v8.3 特别版大小:184.88 MB 更新:2023/03/22
类别:网络监测系统:WinXP, Win7, Win8, Win10, WinAll
分类分类
大小:184.88 MB 更新:2023/03/22
类别:网络监测系统:WinXP, Win7, Win8, Win10, WinAll
Screaming Frog SEO Spider是一款专门用于抓取网址进行分析的网络爬虫开发工具,能够高效地对小型以及超大型网站进行爬网,同时允许用户实时分析结果,可以直接通过程序收集关键的现场数据,以使SEO能够做出明智的决策;支持渲染爬网,通过在执行JavaScript后对渲染的HTML进行爬网,从而抓取AngularJS和React之类的JavaScript框架;支持图片抓取,此功能具有图片链接的所有URI和给定页面中的所有图片,图片超过100kb,缺少替代文字,替代文字超过100个字符;提供用户代理切换器:爬行为Googlebot,Bingbot,Yaho,Slurp,移动用户代理或您自己的自定义UA;强大又实用,需要的用户可以下载体验
1、查找断开的链接、错误和重定向
2、分析页面标题和元数据
3、审查元机器人和指令
4、审计hreflang属性
5、发现重复的页面
6、生成XML站点地图
7、爬网限制
8、抓取配置
9、保存抓取并重新上传
10、自定义源代码搜索
11、自定义提取
12、Google Analytics集成
13、Search Console集成
14、链接指标集成
15、JavaScript渲染抓取
16、自定义robots.txt抓取
1、找到断开的链接
立即抓取网站,找到损坏的链接(404)和服务器错误。批量导出错误和源URL以修复或发送给开发人员。
2、审计重定向
找到临时和永久的重定向,识别重定向链和循环,或者上传一个网址列表,以在网站迁移中进行审计。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并确定在您的网站中过长,短小,缺失或重复的页面标题和元描述。
4、发现重复的内容
使用md5算法检查发现精确的重复网址、部分重复的网页标题、说明或标题等元素,并找到内容较低的网页。
5、使用XPath提取数据
使用CSS Path,XPath或regex从网页的HTML中收集任何数据。这可能包括社交元标签、额外的标题、价格、SKU或更多!
1、需要的用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、通过解压功能将压缩包打开,找到主程序,双击主程序即可进行安装,可以直接安装,也可以自定义安装
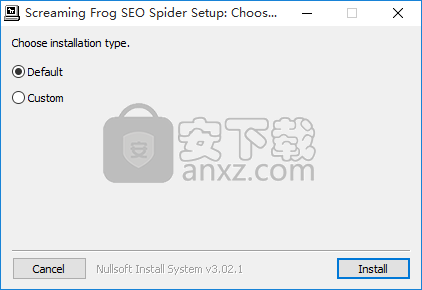
3、点击第二个自定义安装的用户可以根据自己的需要点击浏览按钮将应用程序的安装路径进行更改
4、快捷键选择可以根据自己的需要进行选择,也可以选择不创建
5、现在准备安装主程序。点击“安装”按钮开始安装
6、等待应用程序安装进度条加载完成即可,需要等待一小会儿
7、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
1、程序安装完成后,可以直接点击程序将其打开,同意程序许可协议
2、点击程序注册按钮,点击后即可将应用程序的注册界面打开,可以得到对应的程序界面
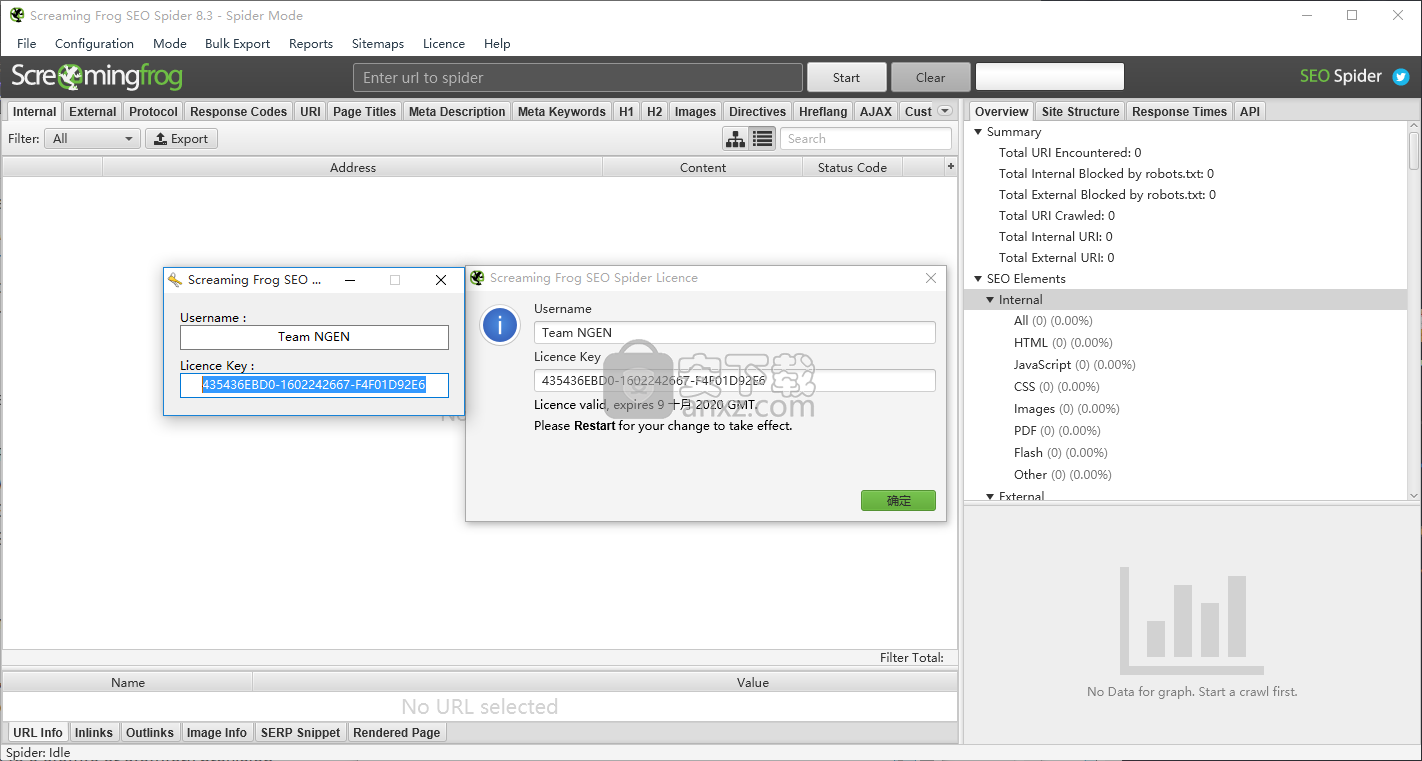
3、打开安装包中的程序注册机,一打开就可以看到对应的程序注册信息
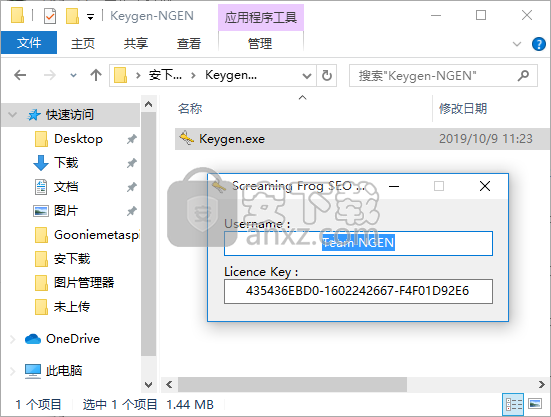
4、将程序注册机中的数据复制到激活对话框中进行激活程序
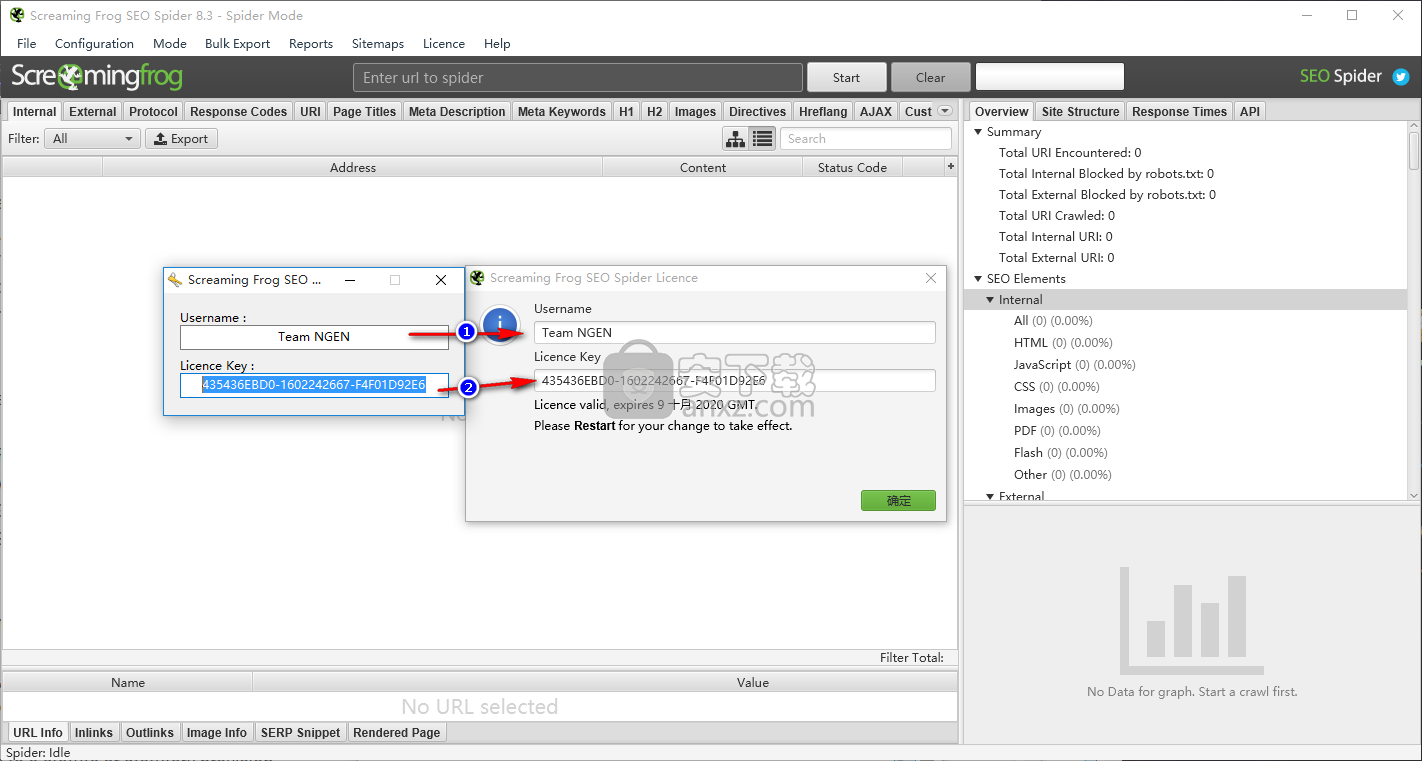
5、激活成功后可以看到一个激活成功界面,点击确认按钮即可享受后的应用程序
运行SEO蜘蛛
SEO Spider可以通过以下两种方式之一运行。
图形用户界面
点击屏幕左下方的“开始”图标,输入“ SEO Spider”以找到它,然后单击它以开始,
故障排除
“打开文件写入错误” –重新启动计算机,然后重试安装。
爬行子文件夹
默认情况下,SEO Spider工具从子文件夹路径向前爬网。只需输入完整的子文件夹URL即可对其进行爬网。
例如,如果是博客,则可能是– https://www.screamingfrog.co.uk/blog/。通过直接将其输入到SEO Spider中,它将抓取/ blog /子文件夹中包含的所有URL。
您可能会注意到,默认情况下,某些不在/ blog /子文件夹中的URL也会被爬网。这是由于“ 开始文件夹之外的检查链接 ”配置所致。
通过此配置,SEO Spider可以将其焦点集中在/ blog /目录中,但当从内部链接到该目录时,仍可以对不在此目录中的链接进行爬行。但是,它不会进一步爬行。这很有用,因为您可能希望找到位于/ blog /子文件夹中的断开链接,但URL结构中没有/ blog /。要仅使用/ blog /抓取URL,只需取消选中此配置即可。
如果子文件夹末尾没有斜杠,例如'/ blog'而不是'/ blog /',则SEO Spider不会将其识别为子文件夹并在其中爬行。如果子文件夹的斜杠版本重定向到非斜杠版本,则同样适用。
要抓取此子文件夹,您需要使用include功能并输入该子文件夹的正则表达式(在此示例中为。* blog。*)。
如果您有更复杂的设置(例如子域和子文件夹),则可以同时指定两者。例如– http://de.example.com/uk/,将.de子域和UK子文件夹等蜘蛛化。
搜寻网址清单
除了通过输入URL并单击“开始”对网站进行爬网外,您还可以切换到列表模式,并粘贴或上载要爬网的特定URL列表。
例如,这对于审核URL和重定向的站点迁移特别有用。我们建议您阅读有关“ 如何在站点迁移中审核重定向 ”的指南,以获取最佳方法。
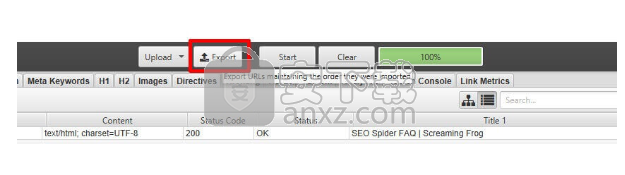
如果您希望以列表模式上载的相同顺序导出数据,请使用用户界面顶部“上载”和“开始”按钮旁边的“导出”按钮。
导出中的数据将以相同的顺序进行,并包含原始上传文件中的所有确切URL,包括重复的文件或执行的任何修复程序
爬行较大的网站
如果您希望执行特别大的爬网,建议您先增加SEO Spider中的RAM内存分配。
如果收到“此爬网内存不足”警告,则需要保存爬网,增加RAM分配并考虑切换到数据库存储模式以保存到磁盘,打开爬网并继续爬网。
SEO Spider可以爬网的URL数量取决于计算机上可用的内存量,是否分配了内存,是否在默认内存存储或数据库存储模式下进行爬网。
对于大型爬网,请阅读我们的有关如何爬网大型网站的指南,其中概述了可用的选项。
您不妨考虑将爬网分成较小的部分,并使用配置来控制爬网。一些选项包括–
如上所述按子域或子文件夹进行爬网。
通过使用include函数来缩小爬网范围,或者通过使用排除或自定义robots.txt功能来排除不需要爬网的区域 。
考虑限制由抓取总网址抓取,深度和数量的查询字符串参数。
通过取消勾选SEO Spider的配置中的图像,CSS,JavaScript,SWF和外部链接,仅考虑对内部HTML进行爬网。
这些都应有助于节省内存并将爬网集中在重要区域上如何爬行大型网站。
可索引和不可索引的是什么意思?
抓取中发现的每个URL都分类为“可索引”或“不可索引”。
“可索引”是指可以抓取,以“ 200”状态代码响应并允许被索引的URL。
“不可索引”是无法被抓取,不会以“ 200”状态代码响应或具有不被索引的指令的URL。
每个不可索引的URL都有一个与之相关的“可索引性状态”,它可以快速解释为什么它不可索引。
不可索引的网址可以包括以下网址-
被robots.txt阻止。
没有反应。
重定向(3XX,元刷新或JavaScript重定向)。
客户端错误(4XX)。
服务器错误(5XX)。
Noindex(或“无”)。
规范化。没有。
SEO Spider将考虑元机器人,X-Robots-Tag,规范链接元素以及用于指令和规范的rel =“ canonical” HTTP标头信息。出于各种原因,网站具有自我引用的元刷新是很常见的,并且通常这不会影响页面的索引编制。但是,由于它正在重定向到自身,因此应进行进一步调查,这就是为什么将其标记为“不可索引”的原因。
要停止将自引用元刷新URL视为“不可索引”,请取消选中“配置>蜘蛛>高级”下的“尊重自引用元刷新”配置。您有API吗?
简而言之,没有。 SEO Spider是您在本地下载,安装和运行的桌面应用程序。因此没有API。
有一个命令行界面以编程方式使用该工具。 SEO Spider还内置有计划功能。
为什么GUI文本出现乱码?
这是由本地字体问题触发的,通常是由于安装了重复的Arial字体引起的。
要调查,请打开“ FontBook”应用程序。转到“编辑->查找已启用的重复项...”以删除所有重复项。解决这些问题后,请尝试重新启动SEO Spider。如果仍然有问题,请返回FontBook并查看您的Arial字体,是否有任何有关它们需要修复的消息?如果是这样,请修复它们并重新启动SEO Spider。如果仍然有问题,请转到“文件->恢复标准字体...”。由此删除的字体将进入“字体簿”中的单独文件夹中,因此您可以根据需要将它们重新添加。
如何在列表模式导出中维持订单?
如果您希望以列表模式以上载的顺序导出数据,请使用用户界面顶部“上传”和“开始”按钮旁边的“导出”按钮。保持出口的清单顺序
导出中的数据将以相同的顺序进行,并包括原始上载中的所有确切URL,包括重复项或执行的任何修正。
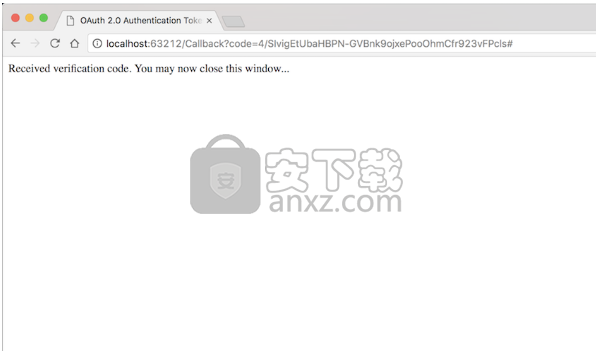
为什么授予我的Google帐户访问权限时出现错误?
在允许SEO Spider访问您的Google帐户后,您应该被重定向到如下所示的屏幕:但是,如果您收到如下错误:您需要检查以下几件事:
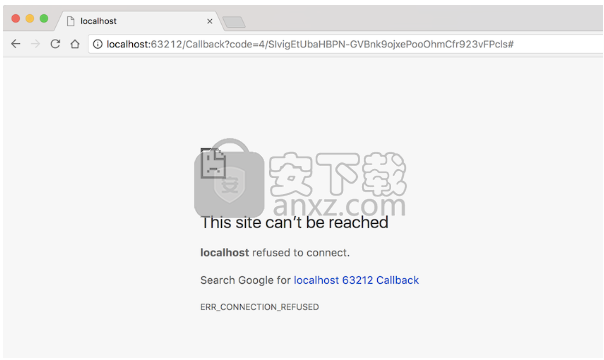
您的计算机上是否运行任何安全软件,阻止SEO Spider侦听URL中指定的端口?该端口是localhost之后的数字:在地址栏中的上方屏幕快照中的63212。
您的浏览器是否将针对本地主机的请求发送给代理?有时您可以告诉您故障屏幕是否提到代理服务器的名称,例如Squid。
推荐什么硬件?
简而言之:对于使用100-200k URL的爬网,一个64位操作系统和8GB RAM就足够了。为了能够抓取数百万个URL,建议使用SSD和16gb的RAM。
硬盘:我们强烈建议您使用SSD并将SEO Spider切换到数据库存储模式,以对大型网站进行爬网。
内存:默认情况下,SEO Spider将所有爬网数据存储在内存中,但可以将其配置为在数据库中存储数据以爬网更多URL。您分配的内存越多,在常规内存存储模式和数据库存储模式下,您将能够爬网的URL越多。为了能够分配超过1gb的内存,您需要一个64位操作系统。过去五年中购买的大多数PC都将运行64位OS。因此,最重要的是确保您有足够的可用内存。每个网站在需要多少内存方面都是唯一的,因此我们无法提供确切的数字来爬网一定数量的URL需要多少内存。作为一个非常粗略的指导,带有8GB RAM的64位计算机通常将允许您在内存存储模式下抓取大约200,000个URL。在数据库存储模式下,这应该允许您爬网大约。 500万个网址。
CPU:爬网的速度通常会受到网站本身的限制,而不是SEO Spider的限制,因为大多数网站都限制了它们将从单个IP接受的并发连接数。抓取成千上万个URL时,某些操作将受到CPU的限制,例如排序和搜索,因此快速的CPU将有助于最大程度地减少这些速度下降。
蜘蛛为什么显示在任务栏中而不显示在屏幕上?
蜘蛛程序正在打开屏幕,可能是由于最近更改了多显示器设置。要将蜘蛛移动到活动监视器上,请使用Alt + Tab选择蜘蛛,然后按住Windows键并使用箭头键将蜘蛛窗口移入视图。
SEO Spider使用什么IP地址和端口?
SEO Spider是从安装它的计算机上运行的,因此IP地址只是该计算机/网络的IP地址。您可以通过在Google中键入“ IP地址”来找出问题所在。
用于连接的本地端口将属于临时范围。连接到的端口通常是端口80(默认的http端口)或端口443(默认的https端口)。如果要爬网的站点或其任何链接指定其他端口,则将连接其他端口
为什么SEO Spider无法抓取我的网站?
这可能有多种原因:
首先要查看的是“内部”选项卡中的状态代码和状态。该站点应以200状态代码和“确定”状态进行响应。但是,如果不是这样,请在爬网时阅读我们的指南,了解常见的HTTP状态代码,它们的含义以及如何解决所有问题。
该网站已被robots.txt阻止。内部标签中的“状态代码”列将为“ 0”,URL的“状态”列将显示为“被Robots.txt阻止”。您可以在“配置> Robots.txt>设置”下将SEO Spider配置为忽略robots.txt。
该站点的行为取决于User-Agent。尝试在Configuration-> HTTP Header-> User Agent下更改User-Agent。
该网站需要JavaScript。清除缓存后,尝试在浏览器中禁用JavaScript的网站。 SEO Spider默认情况下不执行JavaScript,但是在该工具的付费版本中确实具有JavaScript渲染功能。如果网站是在JavaScript框架中构建的,或者具有动态内容,请在“配置>蜘蛛>渲染选项卡> JavaScript”下将渲染配置调整为“ JavaScript”以对其进行爬网。请记住确保JS和CSS文件不会被robots.txt阻止。请参阅有关如何抓取JavaScript网站的指南。
该网站需要Cookies。清除缓存后,能否在浏览器中禁用cookie的情况下查看网站?许可的用户可以通过转到“配置”->“蜘蛛”并在“高级”选项卡中勾选“允许cookie”来启用cookie。
“ nofollow”属性显示在未抓取的链接上。在“基本”标签下的“配置”->“蜘蛛”中有一个选项可以跟随“ nofollow”链接。
该页面具有页面级别的“ nofollow”属性。可以通过HTTP标头中的meta机器人标签或X-Robots-Tag设置。这些可以在“ Nofollow”过滤器的“ Directives”选项卡中看到。要忽略NoFollow指令,请转到“配置”->“蜘蛛网”->,然后勾选“关注内部'不关注'”并重新爬网。
该网站正在使用框架集。 SEO Spider不会抓取frame src属性。
该网站需要一个Accept-Language标头(在Configuration-> HTTP Header中添加标头调用“ Accept Language”,其值为“ en-gb”)。
Content-Type标头未指示该页面是HTML。这显示在“内容”列中,并且应该是text / html或application / xhtml + xml。 JavaScript呈现模式将另外检查页面内容以查看是否已指定,例如:
为什么SEO Spider冻结?
这通常是由于SEO Spider达到了其内存限制。请阅读如何增加内存。
为什么会收到“连接错误”响应?
如果根本没有收到响应,则连接错误或连接超时是一条消息。通常这是由于网络问题或代理设置。请检查您是否可以连接到互联网。如果更改了SEO Spider代理设置(在配置下,代理),请确保这些设置正确(或已关闭)。
为什么会收到“ 403 Forbidden”错误响应?
当网络服务器出于某种原因拒绝访问SEO Spider的请求时,就会出现403禁止状态代码。
如果这种情况持续发生,并且您可以在浏览器中看到该网站,则可能是Web服务器的行为取决于用户代理。在高级版本中,尝试在Configuration-> HTTP Header-> User Agent下调整User Agent设置。例如,尝试以漫游器(例如“ Googlebot Regular”)或浏览器(例如“ Chrome”)进行爬网。
如果在爬网期间间歇性地发生这种情况,则可能是由于Spider请求页面的速度使服务器不堪重负。在SEO Spider的高级版本中,您可以降低请求速度。如果您使用的是“精简版”版本,则可能会发现右键单击该URL并选择“重新蜘蛛”会有所帮助。
为什么我在浏览器中遇到不同的响应?
SEO Spider HTTP请求通常不同于传统的浏览器和其他工具,因此与访问页面或使用其他工具检查响应相比,有时您会遇到不同的响应。
SEO Spider仅在服务器发出请求时报告服务器给出的响应,这虽然不正确,但可能会与其他地方有所不同。在SEO Spider中可配置的一些可能导致服务器做出不同响应的常见因素是-
用户代理-默认情况下,SEO Spider使用它自己的用户代理,浏览器也是如此。您可以在“配置> HTTP标头>用户代理”下找到用户代理配置。如果将其调整为浏览器用户代理(Chrome等),则可能会遇到不同的响应。
Cookies-默认情况下,SEO Spider不接受Cookie(类似于Google)。但是,浏览器可以。如果您在浏览器中禁用Cookie,则可能会看到该页面不再加载,向URL发出会话ID或重定向到其自身。您可以在“配置>蜘蛛>高级”下“允许cookie”。
JavaScript-浏览器将执行JavaScript,默认情况下SEO Spider不执行。因此,您可能会遇到页面内容的细微变化,如果使用JavaScript框架构建网站,或者在浏览器中将其完全重定向到新位置,则差异可能会更大。与Google类似,SEO Spider可以呈现网页,并在JavaScript发挥作用后对其进行爬网。您可以通过导航到“配置>蜘蛛>渲染”并选择“ JavaScript渲染”来启用此功能。与浏览器相比,底部的“渲染页面”选项卡将帮助调试SEO Spider可以看到的差异。如果您的网站是使用JavaScript框架构建的,则请阅读我们的“如何抓取JavaScript网站”指南。
接受语言标头-您的浏览器将提供您所用语言的接受语言标头。与Googlebot类似,默认情况下,SEO Spider不为请求提供Accept-Language标头。但是,您可以在“配置> HTTP标头>接受语言”下调整接受语言配置。
速度-在压力和负载下,服务器可以做出不同的响应。他们的反应可能不太稳定。我们建议降低爬网速度,查看响应是否随后发生变化,并使用WireShark独立验证响应。
Savvius Omnipeek(数据包分析软件) 网络监测274.0 MBv11.0.1
详情charles windows(网络封包分析工具) 网络监测63.2 MBv4.5.6
详情TMeter(宽带仪表软件) 网络监测12.47 MBv18.0.875
详情httpwatch(网页数据分析工具) 网络监测25.3 MBv12.0.3 官方版
详情IP-Guard(威盾) 3.50.0918 网络监测75.00 MB
详情HostScan(网络主机扫描) 网络监测0.73 MBv1.6 汉化版
详情ixchariot(网络测试工具) 网络监测169.89 MBv6.7
详情Charles 网络监测133.0 MBv4.2
详情网路岗 9.02.89 简体中文 网络监测27.00 MB
详情局域网扫描 Nsasoft Hardware Software Inventory v1.5.3.0 网络监测3.00 MB
详情Screaming Frog SEO Spider(网络爬虫开发工具) 网络监测184.88 MBv8.3 特别版
详情p2p网络终结者 网络监测3.02 MBv4.34 绿色版
详情imacros(web自动化工具集) 网络监测40.81 MBv10.4.28 特别版
详情NetResident 网络嗅探 v2.1.592 网络监测20.00 MB
详情ByteOMeter 1.2.0 汉化 网络监测0.93 MB
详情SiteMonitor Enterprise(网站监测工具) 网络监测19.4 MBv3.95
详情HomeGuard(电脑系统监控工具) 网络监测33.35 MBv9.01
详情NetLimiter 3.0.0.11 汉化 网络监测6.00 MB
详情Net-Peeker(网络监视软件) 网络监测13.3 MBv4.0
详情SolarWinds OrionNPM 网络监测297.12 MBv10
详情WPE中文版 网络监测1.08 MB附带使用说明
详情charles windows(网络封包分析工具) 网络监测63.2 MBv4.5.6
详情EtherPeek NX 3.0 (网络协议分析利器) 网络监测25.00 MB
详情acunetix wvs11 网络监测91.3 MB附安装教程
详情BluetoothView(蓝牙检测工具) 网络监测0.05 MBv1.66 官方最新版
详情Sniffer Pro 4.70.530 汉化注册版 网络监测35.00 MB
详情聚生网管2011 5.18.18 网络监测5.00 MB
详情Acunetix Web Vulnerability Scanner 网络监测74.9 MBv12.0
详情WebSite-Watcher(网站监控工具) 网络监测102 MBv20.3
详情Burp Suite Pro 2020(渗透测试工具) 网络监测336.52 MBv2020.5.1
详情网速检测(NetPerSec)你的网速到底有多少? 网络监测0.08 MB
详情IP-Guard(威盾) 3.50.0918 网络监测75.00 MB
详情Charles 网络监测133.0 MBv4.2
详情Burp Suite 2020补丁 网络监测1.85 MB附带安装教程
详情Zenmap(端口扫描工具) 网络监测26.26 MBv7.70 官方中文版
详情SolarWinds OrionNPM 网络监测297.12 MBv10
详情Serial Port Monitor(COM端口监控软件) 网络监测8.88 MBv8.0 免费版
详情gephi中文版 网络监测71.70 MBv0.9.2 官方免费版
详情流媒体探测器 网络监测1.46 MB
详情局域网IP扫描工具(SoftPerfect Network Scanner) 网络监测6.0 MBv7.2.3 官方版
详情网络监控重启工具 网络监测0.31 MBv1.0.9.5 绿色版
详情wireshark(网络分析工具) 网络监测67.83 MBv3.4.7中文版
详情网络封包分析工具 Wireshark v3.4.7中文版 网络监测67.83 MBv3.4.7中文版
详情TraceRouteOK(路由追踪工具) 网络监测0.15 MBv2.66
详情D盾啊D保护盾 网络监测6.28 MBv2.1.6.3
详情网速管家客户端 网络监测66.16 MBv2.2.2 官方版
详情网络数据包嗅探专家 4.53 绿色版 网络监测2.00 MB
详情网络地址嗅探 URL Snooper 2.37.01 注册版 网络监测1.42 MB
详情宽带检测工具 网络监测0 MB
详情网络流量监测(NetPerSec) 网络监测0.08 MB
详情